Server-Infrastruktur
Dieses Kapitel beschäftigt sich mit der grundlegenden Softwarearchitektur von Webanwendungen und gibt uns einen Überblick über bewährte und neue Technologien Realisierung von Webanwendungen.
Der praktische Fokus liegt auf Docker und wie derartige Technologien in containerisierten Anwendungen eingesetzt werden können. Wir werden uns zunächst mit drei einschlägigen Technologie-Stacks (LAMP-Stack, MEAN-Stack und JAM-Stack) beschäftigen und dann die Architektur von Webanwendungen und die damit verbundenen Software-Architekturen analysieren.
Was ist eine Webanwendung?
Eine Webanwendung ist ein client-server-basiertes, betriebssystemunabhängiges Anwendungsprogramm, das meist im Browser ausgeführt wird. Abhängig vom Architekturmuster einer Webanwendung können die Geschäftslogik und die Datenverarbeitung weitgehend auf dem Server (thin client) oder im Client erfolgen (fat client). Im Kontext der „mobilen Revolution“ und des Cloud-Computing wird der Begriff zunehmend generalisiert verwendet für Software, die sich zum maßgeblichen Teil auf HTTP-APIs stützt.
Die Architektur von Webanwendungen kann sehr unterschiedlich sein. Generell ist aber festzuhalten, dass es aufgrund der Zustandslosigkeit des HTTP-Protokolls meist eine Persistenzschicht (Datenhaltung), Anwendungsschicht (Funktionslogik) und Präsentationsschicht gibt (3-Layer-Architektur). Die server- sowie die clientseitige Implementierung dieses Drei-Schichten-Modells kann unterschiedlich realisiert werden.

Grafik: Klassischer Aufbau einer Webanwendung in 3-Layer-Architektur
Quelle: Torsten Schrade
Mit dem Zuwachs im Bereich von Virtualisierung und Cloud Computing verschwimmt das “klassische” Architekturmuster von Webanwendungen. Applikationen werden zunehmend in kleine Komponenten gekapselt, die in einer verteilten Infrastruktur isolierte Aufgaben wahrnehmen und über webbasierte APIs miteinander kommunizieren. Man spricht in diesem Fall von microservices-orientierten Architekturen.
Weitere Informationen
Softwarestacks für Webanwendungen
Ein Softwarestack ist eine Kombination von Softwarekomponenten, die gemeinsam eine Anwendung bilden. In der Regel wird ein Softwarestack durch eine bestimmte Architektur geprägt. Im Bereich von Webanwendungen sind einige Softwarestacks besonders verbreitet. In diesem Kapitel werden wir uns mit drei dieser Softwarestacks beschäftigen: dem LAMP-Stack, dem MEAN-Stack und dem JAM-Stack.
Info
Der Begriff Stack ist ein Akronym für Software Technology Architecture Component Kit. Ein Stack ist also ein Softwarepaket, das aus mehreren Komponenten besteht. Die Komponenten eines Stacks sind meist aufeinander abgestimmt und bilden gemeinsam eine Anwendung.
LAMP-Stack
Der LAMP-Softwarestack gehört zu den traditionellen Architekturen zur Bereitstellung von Webanwendungen. Das Akronym LAMP steht für eine Kombination von Linux (Betriebssystem), Apache (Webserver), MySQL (Datenhaltung) und PHP (Programmiersprache, Anwendung). Das Softwarepaket besteht vollständig aus quelloffenen Komponenten und ist bereits seit den 1990iger Jahren etabliert. In der klassischen Architektur des LAMP-Stack wird die Skriptsprache PHP als Modul in den Webserver eingebettet. HTTP-Anfragen an den Webserver werden von diesem – je nach Dateiendung – entweder direkt ausgeliefert oder zur dynamischen Weiterverarbeitung an den PHP-Interpreter überwiesen. Zugriffe auf eine Datenbank erfolgen wiederum durch den PHP-Interpreter.
Einigen Statistiken zufolge wird die Kombination von Apache-Webserver und PHP nach wie vor am häufigsten zur Erstellung dynamischer Webanwendungen eingesetzt (W3Tech: Apache Usage, W3Tech: PHP Usage). Gründe hierfür sind die übergreifende Verfügbarkeit dieser Pakete, die hohe Dokumentationsdichte, die einfache Erlernbarkeit von PHP sowie die Stabilität des Gesamtpakets.
In jüngerer Zeit werden Komponenten der traditionellen LAMP-Architektur zuweilen mit neueren Produkten ersetzt. Im Bereich des Webservers kommt häufiger nginx zum Einsatz, im Bereich der Datenbank vor allem MariaDB (seit dem Erwerb von MySQL durch die Firma Oracle). Wird nginx (“Engine X”) als Webserver eingesetzt spricht man zuweilen auch von einem LEMP-Stack.
Praxis mit dem LAMP-Stack
Mit Hilfe des Dockerimage fauria/lamp können Sie eine auf alle notwendigen Essentials komprimierte Version eines LAMP-Stack ausprobieren. Starten Sie bei sich eine Instanz des Images:
docker run -dit --rm -p 8080:80 --name lamp fauria/lamp
Sie können sich auch in den laufenden Container einloggen:
docker exec -e TERM=xterm -i -t lamp bash
Aufgaben
- Führen Sie einen GET-Request auf den Webserver im Container aus und analysieren Sie die Antwort. Hierfür kann z.B. das Firefox-Add-On RESTer verwendet werden.
- Rufen Sie die Datei
index.phpim Browser auf und sehen Sie sich die Ausgabe vonphpinfo()an. - Im Container: Analysieren Sie die Webserver-Logfiles in
/var/log/apache2/access.log. - Im Container: Melden Sie sich mit
mysql -urootauf der Konsole des MySQL-Servers an und lassen Sie sich mitSHOW DATABASES;alle Datenbanken anzeigen.
MEAN- bzw. MEVN-Stack
Die Anforderungen an moderne Webanwendungen beginnen sich zunehmend zu verändern. Ausgelöst durch die schnellen Entwicklungen im Bereich von Smartphones und Tablets verschwimmen die Grenzen zwischen Desktop- und Webanwendungen zunehmend. Es spielt immer weniger eine Rolle, ob eine Anwendung nativ installiert ist oder webgetrieben auf einem Gerät läuft. Aus Nutzersicht fühlt sich der Umgang mit der Anwendung häufig gleich an. Die meisten mobilen Anwendungen verwenden zudem HTTP-basierte Schnittstellen und Web-APIs. Mit dieser Entwicklung geht eine “Renaissance” der Programmiersprache JavaScript einher. Während JavaScript in den Anfängen des Web vor allem in der Präsentationsschicht einer Webanwendung zum Einsatz kam, ist durch die Entwicklung von node.js ein übergreifender Einsatz von JavaScript in allen Architekturschichten möglich geworden.
Neben node.js haben sich (maßgeblich vorangetrieben durch die Internetkonzerne) leistungsstarke Full-Stack JavaScript Frameworks entwickelt (zum Beispiel Angular, Vue oder React). Diese Entwicklung ist bedeutsam, da somit Anwendungen “aus einem Guß” nativ in JavaScript realisiert werden können. Neben den traditionellen LAMP-Stack treten also zunehmend JavaScript-getriebene Laufzeitumgebungen.
Eine inzwischen verbreitete Form eines solchen JavaScript-Webstacks ist der MEAN-Stack. Das Acronym steht für MongoDB (dokumentenorientierte Datenbank), Express (Backend-Framework), Angular (Frontend-Framework) und Node (serverseitige Laufzeitumgebung). Als Austausch- und Speicherungsformat für Daten wird innerhalb des MEAN-Stacks JSON eingesetzt. Je nach verwendetem JavaScript-Framework finden sich manchmal auch alternative Bezeichnungen wie MEVN (das V steht für Vue.js) oder VENOM (Vue, Express, Node, MongoDB).

Grafik: Architektur einer Webanwendung mit dem MEAN-Stack
Quelle: Torsten Schrade
Die Komponenten dieser JavaScript-Stacks kommunizieren HTTP-basiert über Schnittstellen miteinander. Es liegt bei der Verwendung eines solchen Stacks ganz in der Entscheidung des Entwicklungsteams, ob die Anwendung eher client- oder serverseitig oder sogar paritätisch implementiert wird. Die Technologie lässt aufgrund der durchgängigen Verwendung von JavaScript sehr große Spielräume.
Praxis mit dem MEAN-Stack
Klonen Sie sich mit git clone git@gitlab.rlp.net:studiengang-digitale-methodik/modul-7/mevn-app die Dateien für eine MEVN-Stack. Wechseln Sie dann in das neu entstandene Verzeichnis mevn-app und führen Sie hier auf der Kommandozeile den Befehl docker compose up -d aus.
Damit starten Sie eine Docker-Anwendung, die aus mehreren Containern besteht, in denen verschiedene Teile der Anwendung laufen. Es gibt zwei Weboberflächen:
- die öffentliche Website (das Frontend) unter http://localhost:3000/, die bei einer ’echten’ Anwendung für alle zugänglich wäre, und
- die Datenbank-Administrationsoberfläche (das Backend) unter http://localhost:8081/, die nur für Administratoren der Anwendung verfügbar wäre. Bevor Sie auf diese URL zugreifen können, werden Sie vom Browser nach Zugangsdaten gefragt. Geben Sie hier
fooals Nutzer:innennamen undbarals Passwort ein.
Aufgaben
-
Erstellen Sie über das Backend eine neue Datenbank namens
cats. Mit der SchaltflächeViewgelangen Sie “in” die Datenbank, die bisher noch keine Collections enthält. Legen Sie in der Datenbank eine neue Collection an, ebenfalls mit dem Namencatsund benutzen Sie anschließend wiederView. In der Collection erstellen Sie nun bis zu vier neue Dokumente (d.h., Einträge), wobei sie folgende JSON-Datensätze verwenden können:{"_id":1,"name":"Mr Snuffles"}{"_id":2,"name":"Findus"}{"_id":3,"name":"Fat Freddy's Cat"}{"_id":4,"name":"Pixel"}
-
Probieren Sie nun das Frontend aus. Verfolgen Sie in der Konsole oder der Netzwerkansicht der Entwickler-Tools in Ihrem Browser, welche Requests die Anwendung zu welchem Zeitpunkt schickt.
-
Schauen Sie sich in Ordner
mevn-appdie Dateiendist/app.jsundserver.jsan. Welche Gemeinsamkeiten sowie Unterschiede fallen Ihnen auf und welchen Zweck würden Sie beiden Dateien zuschreiben? -
Derzeit wird die Liste im Frontend nur durch einen Reload oder nach einer Eingabe aktualisiert. Wäre es Ihrer Ansicht nach möglich, die Frontend-Darstellung bei Veränderung der Daten (z.B. über das Backend) automatisch zu aktualisieren?
JAM-Stack
Der Begriff JAM-Stack wurde vor einigen Jahren von den Gründern der Firma Netlify ins Leben gerufen, um einen neuen Architekturansatz für Webanwendungen zu bezeichnen, der die drei Komponenten JavaScript, APIs und Markup miteinander verbindet. Interessant ist hierbei, dass der Ansatz durch die (automatisierte) statische Erzeugung von Websites aus Markup (sehr häufig: Markdown) mittels Static Site Generators in gewisser Hinsicht zu den Ursprüngen des Webs zurückkehrt. Durch den Einsatz von modernem JavaScript, die im Rahmen der statisch ausgelieferten Websites clientseitig dann aber HTTP-basierte APIs und cloud-basierte Microservices ansprechen und auf diese Weise auch dynamische Funktionalitäten (wie bspw. ein User Management oder eine Suche) in den statisch vorerzeugten Sites abbilden unterscheidet sich der Ansatz deutlich vom LAMP- oder MEAN-Stack.

Grafik: Architektur einer Webanwendung mit dem JAM-Stack
Quelle: Torsten Schrade
Der JAM-Stack lässt sich außerordentlich gut in cloud-basierten Infrastrukturen realisieren und hat bei bestimtmen Anwendungszenarien (insbesondere im Bereich Performance und Sicherheit) einige Vorteile. Gleichzeitig ist der JAM-Stack kein ausschließlicher Ersatz für dynamisch arbeitende Web-Stacks, die wiederum andere Vorteile (z.B. einfache Verwaltung der Inhalte, einfaches Hosting der Daten “on premise” etc.).
Praxis mit dem JAM-Stack
Viele JAM-Stack-Lösungen bringen umfangreiche Frameworks mit. Eine besonders schlanke Lösung, die sich ausgezeichnet für den Einstieg in den JAM-Stack eignet, ist der Harp-Websever. Harp liefert Markdown und JavaScript-basierte Dateien ganz ohne zusätzliche Softwarekomponenten als statische HTML-Seiten aus. Dazu müssen diese Dateien einfach in Verzeichnisse auf dem Webserver gelegt werden. Auf diese Weise ist es z.B. sehr einfach, Markdown-Inhalte, die über ein Git-Repositorium verwaltet werden, ohne zusätzliche Software (bis auf Harp) direkt online zu publizieren.
Legen Sie sich zunächst einen neuen Ordner an (z.B. harp) und legen Sie in dem Ordner eine neue Datei namens index.md an. Schreiben Sie # Hello world from Markdown in die Datei und speichern sie diese.
Im Ordner harp führen Sie nun folgenden Befehl auf der Kommandozeile aus:
docker run -d -p 9000:9000 -v ./:/var/www/server --name harp --rm registry.gitlab.rlp.net/studiengang-digitale-methodik/modul-7/harp-container
Nach dem Start steht der Harp-Webserver unter http://localhost:9000 bereit.
Sie können nun beliebig weiteren Markdown-Inhalt in die index.md schreiben. Nach einem Reload im Browser wird der Markdown-Content sofort als HTML im Browser angezeigt.
Nehmen Sie weitere Experimente mit Markdown, einem CSS-Preprocessor oder einer Javascript-Template-Engine vor. Inspirationen gibt es in der Harp Dokumentation.
Weitere Informationen
Info
Die Sturm-App verwendet keinen dieser Stacks. Die App läuft auf Linux (Alpine), verwendet einen Lighttpd-Webserver, greift über eine API auf die Daten der katalogisierten Briefen zu und nutzt PHP als Programmiersprache.
Virtuelle Maschinen und Anwendungscontainer
Immer weniger Webanwendungen werden heute über physische Systeme (dedizierte Systeme) bereitgestellt. Durch große Fortschritte im Bereich der Virtualisierung werden Anwendungen vielmehr auf virtuellen Maschinen oder in Anwendungscontainern betrieben. Hierbei wird eine Abstraktionsschicht zwischen die eigentliche Hardware und die Software (häufig das Betriebssystem) gelegt. Dienste wie z.B. das Betriebssystem, der Arbeitsspeicher oder auch die Netzwerkressourcen werden emuliert und mittels Virtualisierungsprogammen gesteuert. Durch diese Vorgehensweise können die Ressourcen, die einer Webanwendung im Betrieb zur Verfügung stehen, deutlich besser skaliert werden, als dies bei einem direkten Betrieb auf physischer Hardware der Fall wäre. Virtualisierung ermöglicht eine stärker gekapselte Anwendungsarchitektur. Insbesondere die Entwicklung von Anwendungscontainer-Lösungen wie Docker hat dazu geführt, dass moderne Webanwendungen zunehmend als Microservices erstellt werden. Bei diesem Architekturmuster besteht eine Webanwendung aus voneinander unabhängigen (virtualisierten) Komponenten (bzw. Prozessen), die über standardisierte Schnittstellen und Protokolle (HTTP) kommunizieren.
Folgende Darstellung gibt einen Überblick über die Unterschiede zwischen virtuellen Maschinen und Anwendungscontainern:

Grafik: Virtuelle Maschine vs. Anwendungscontainer
Quelle: Torsten Schrade
Betrieb von Webanwendungen
Sofern eine Webanwendung sich nicht nur an eine sehr kleine Gruppe von Nutzer:innen wendet, stellen sich auch Fragen zu Skalierbarkeit der Anwendung sowie zu ihrer Instandhaltung und kontinuierlichen Aktualisierung.
Skalierbarkeit und verteilte Systeme
Insbesondere im Bereich hochperformanter Webanwendungen mit Millionen Anfragen pro Tag ist es notwendig, die Systemlast zu verteilen und Anwendungen zu skalieren. Eine Anwendung kann vertikal (scale-up) oder horizontal (scale-out) skaliert werden. Bei der vertikalen Skalierung werden einem Rechner mehr Ressourcen hinzugefügt (z.B. mehr Arbeitsspeicher oder mehr CPUs). Bei der horizontalen Skalierung werden zusätzliche Rechner zum Gesamtsystem hinzugefügt, wobei die Anwendung weiterhin einen Einstiegspunkt hat. Vertikale Skalierbarkeit hat eine physische Obergrenze (ein Rechner lässt sich nur bis zu einem bestimmten Grad aufrüsten), horizontale Skalierbarkeit kann softwaretechnische Grenzen haben (z.B. wenn sich eine Software nicht gut parallelisieren lässt).
In der Praxis sind häufig Mischformen im Einsatz. Hierbei werden spezifische Dienste einer Webanwendung von einander getrennt und als separate Systeme betrieben (z.B. Webserver und Datenbankserver). In einem solchen Fall spricht man von einem verteilten System. Gleichzeitig können die Komponenten des verteilten Systems (meist durch Virtualisierung) im Betrieb mit mehr Ressourcen ausgestattet werden. Bei Lastspitzen können die Webserver in einer virtualisierten verteilten Umgebung bspw. on-the-fly mehr Arbeitsspeicher zugewiesen bekommen. Daneben können auch spezialisierte Rechnerknoten (bspw. ein Load Balancer) eingesetzt werden.
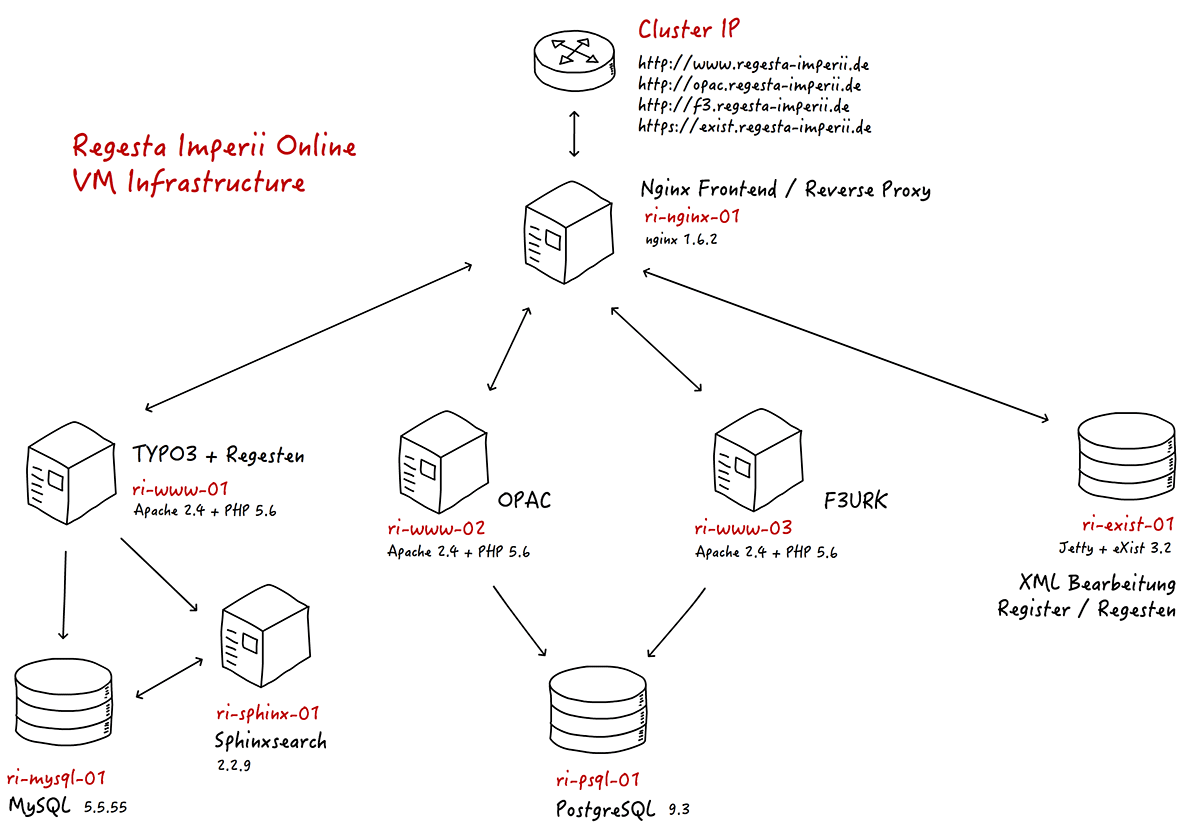
Grafik: Verteilte, cloudbasierte VM-Infrastruktur der Regesta Imperii (n-tier)
Quelle: Torsten Schrade
Grundsätzlich gilt die Regel, je verteilter das System, umso komplexer das Deployment bzw. das Roll-Out einer Webanwendung. Verteilte Systeme werden durch die Fortschritte im Bereich von Anwendungscontainern immer mehr zum Standard.
Praxis mit verteilten Systemen
Schauen Sie erneut in den Ordner, mevn-app, den Sie für die Praxisaufgaben mit dem MEAN-Stack geklont haben (falls noch nicht, können Sie das jetzt tun).
Aufgaben
- Recherchieren Sie, was mit dem Befehl
docker composeerreicht wird und überlegen Sie, wie sich diese Strategie vom Gebrauch vondocker rununterscheidet. - Schauen Sie sich die Datei
docker-compose.ymlim Ordnermevn-appan. Welche Systeme gibt es hier und warum ist es Ihrer Ansicht nach sinnvoll (oder auch nicht), diese wie hier angelegt zu modularisieren?
Weitere Informationen
Orchestrierung und Automation
Die Automation von Prozessen spielt im alltäglichen Betrieb von Webanwendungen eine wichtige Rolle. Automation führt zur Steigerung der Ergebnisqualität, da Fehlerquellen in einem Prozess reduziert und die Nachvollziehbarkeit insgesamt erhöht werden.
Automation kann an vielen Stellen im Lebenszyklus einer Webanwendung erreicht werden. Dies beginnt schon in der Planungsstufe (bspw. durch die automatisierte Bereitstellung von “Projektgerüsten” in einem Projektmanagement-Tool), erstreckt sich aber auch auf die Softwareentwicklung (durch die automatisierte Erzeugung von “Blaupausen” für eine Webanwendung mit einem Build-Tool (sog. Scaffolding), die Paketierung und das Testing von Software (über Continuous-Integration-Instrumente und Testing-Tools) sowie den Infrastrukturbereich (in Form der automatisierten Bereitstellung virtueller Entwicklungs- und Produktivsysteme).
Im Bereich der Infrastruktur spricht man auch von der Orchestrierung der Systeme. Hierbei werden meist textbasierte (und somit versionierbare) “Baupläne” der für die Webanwendung notwendigen Systeme und Anwendungscontainer erstellt. Webanwendungen werden also nicht mehr von Hand installiert und konfiguriert, sondern mithilfe von Konfigurationsmanagement-Instrumenten automatisiert “ausgerollt”. Häufig wird die Produktivumgebung einer Webanwendung erst bei der Auslieferung einer bestimmten Version on-the-fly erstellt.
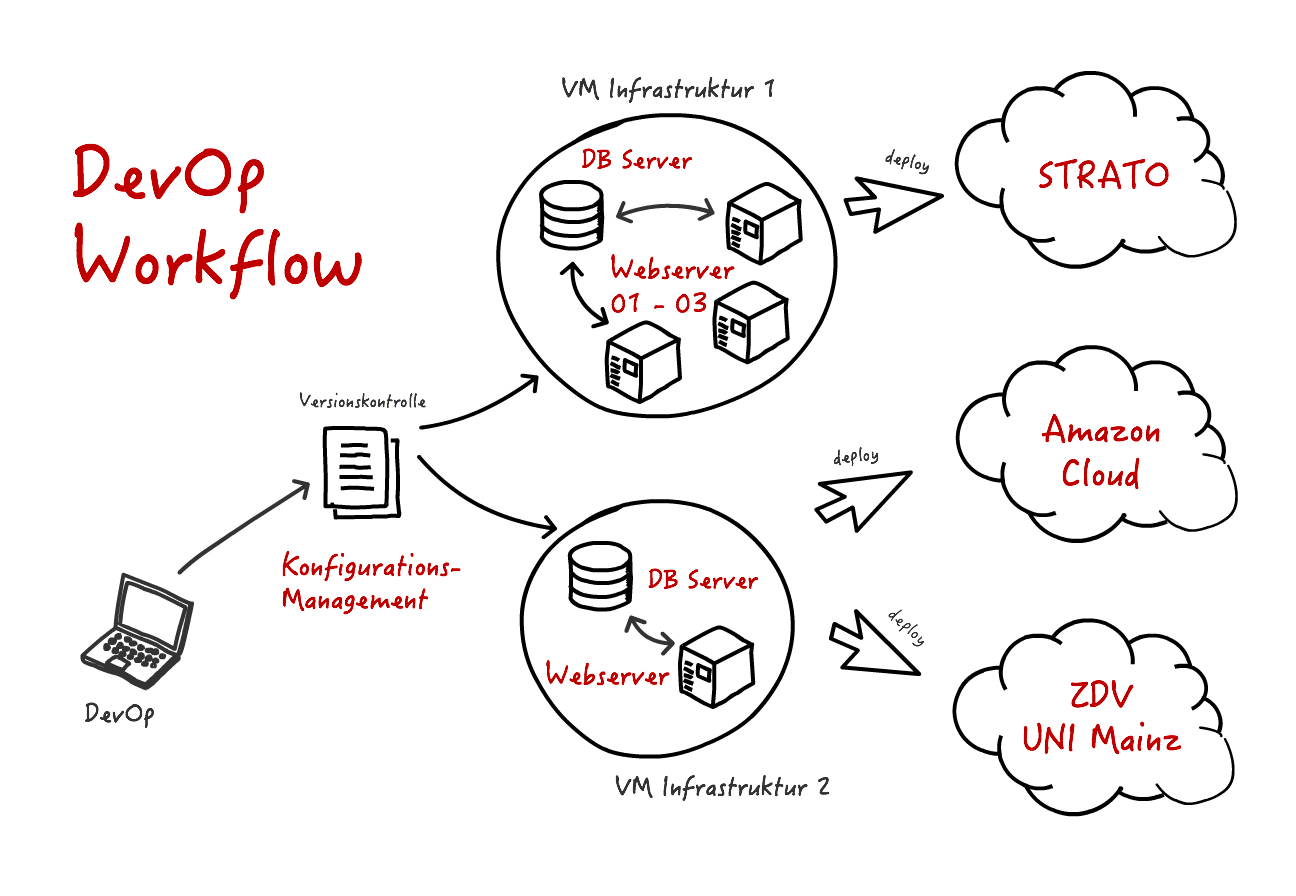
Grafik: Orchestrierung und Automation von Infrastruktur
Quelle: Torsten Schrade
Praxis mit Automation
Der Docker-Container registry.gitlab.rlp.net/studiengang-digitale-methodik/modul-7/sturm-app-container, in dem Ihre lokale Version der Sturm-App läuft, hat zwei eingebaute Test-Mechanismen.
Der erste ist für sogenanntes Code-Sniffing und kann verwendet werden, um zu prüfen, ob Ihr PHP-Code die Anforderungen der PSR-12-Style-Spezifikationen erfüllt. Wenn Ihre lokale Sturm-Anwendung läuft, kann dieser Test über die Kommandozeile mit
docker exec sturm-app /var/www/localhost/vendor/bin/phpcs --standard=phpcs.xml
ausgeführt werden.
Der zweite ist für sogenannte statische Code-Analyse und kann verwendet werden, um die logische Konsistenz Ihres PHP-Codes zu prüfen, ohne dass der Code ausgeführt werden muss. Dieser Test kann mit
docker exec sturm-app /var/www/localhost/vendor/bin/phpstan analyze -c phpstan.neon --memory-limit 512M
ausgeführt werden.
Aufgabe
Das Team-Repositorium im GitLab RLP soll nun mit einer Pipeline ausgestattet werden, die beim Push in den main-Branch ausgelöst wird. Die Pipeline soll für jeden der o.g. Tests je einen Test-Job ausführen.
Lesen Sie dafür die GitLab CI/CD Quick Start Doku. Hilfreich für die Optionen, die in der .gitlab-ci.ymlzur Verfügung stehen, ist die YAML Dokumentation
.
Erstellen Sie dann in Ihrem Team-Repositorium die Datei .gitlab-ci.yml auf oberster Ebene und versuchen Sie, damit den folgenden Ablauf zu modellieren:
Als erstes in der Pipeline eine Instanz der Sturm-App gestartet werden, analog zum Start der Anwendung auf Ihrem lokalen Rechner. Dafür muss in der Umgebung, in der die Pipeline läuft, zunächst das Docker-Image des Sturm-App-Containers geladen werden.
Um das in der Pipeline-Umgebung möglich zu machen, muss die Pipeline in einem Docker-Container für Docker laufen, der als Service Docker-in-Docker (dind) enthält (ein Art forgeschrittenes Inception-Szenario). Sie benötigen darum die Einträge
image: docker:latest
und
services:
- docker:dind
Schauen Sie sich in diesem Zusammenhang auch gern den Dokumentationsabschnitt zum Gebrauch von Docker-Images in der GitLab-CI an.
Da es sich bei der Container-Registry des Modul 7 um eine private Registry handelt, muss ein Login erfolgen, bevor der Ihnen bereits bekannte Befehl docker run ausgeführt werden kann. Das geht mit in der Pipeline mit
docker login -u "$CI_REGISTRY_USER" -p "$CI_REGISTRY_PASSWORD" registry.gitlab.rlp.net
$CI_REGISTRY_USER und $CI_REGISTRY_PASSWORD sind Platzhalter für Zugangsdaten, die zu diesem Zweck im GitLab RLP hinterlegt wurden.
Danach kann der Sturm-App-Container gestartet werden. Der Verzeichnispfad mit der eigentlich Anwendungslogik, welche in den Container gemounted wird, ist in diesem Fall jedoch ein anderer. Als Volume-Option muss in der Pipeline -v ./:/var/www/localhost/htdocs/ verwendet werden.
Sowohl der Login als auch das Starten des Sturm-App-Containers müssen für jeden Job separat ausgeführt werden, da die Pipeline-Jobs von GitLab nicht hintereinander sonder parallel ausgeführt werden. Schauen Sie sich darum am besten die Konfigurationsoption before_script an, um Wiederholungen zu vermeiden.
Konfigurieren sie anschliessen zwei Jobs, die o.g. Tests ausführen.
Die .gitlab-ci.yml Dateien können mit einem Linter in GitLab auf strukturelle Validität geprüft werden.
Nach einem ersten Push der validen .gitlab-ci.yml in das Team Repository wird automatisch eine Pipeline angelegt und kann auf der jeweiligen Team-Seite aufgerufen werden (Beispiel: Pipeline des Sturm-App-Containers).
Eine Musterlösung steht in der .gitlab-ci.yml im CI-Branch
der Sturm-App zur Verfügung. Eine erfolgreich durchgelaufene Beispiel-Pipeline findet sich ebenfalls in diesem Repository. Ein Klick auf die Jobs zeigt den Shell-Output an, der während des Pipeline-Durchlaufs für den jeweiligen Job erzeugt wurde.
Weitere Informationen
Deployment von Webanwendungen
Der Prozess des Deployments, also der Bereitstellung einer Webanwendung, hat sich in den vergangenen Jahren grundlegend gewandelt. Wurden spezifische Codestände früher häufig von Hand per FTP oder SCP auf einen Webserver übertragen und dort bereitgestellt, erfolgt dieser Prozess heute meistens unter Verwendung eines Versionskontrollsystems und darauf angelegter Trigger (Auslöser), die eine Aktion in einer Deployment-Pipeline auslösen. In einer einfachen Form kann dies mithilfe von Webhooks geschehen, die bei einem Commit in einen Branch eines Code-Repositories ausgelöst werden und eine HTTP-basierte Aktion auf einem Drittsystem anstoßen.

Grafik: Einfaches Deployment eines Git-Repositoriums über Webhooks
Quelle: Torsten Schrade
Im Bereich professioneller Webanwendungen, die zunehmend auf containerbasierte Multikomponenten-Architekturen setzen, können Deployment-Szenarien deutlich komplexer ausfallen, da beim Ausrollen der Software die vollständige Infrastruktur erzeugt wird (Laufzeitumgebung für den Programmcode, Datenbanksystem, Webserver, Caches etc.). Folgende Grafik gibt hierzu ein Beispiel:

Grafik: Komplexes Cloud-Deployment einer Multikomponenten-Webanwendung
Quelle: User DDuvall (WMF) and UserTCipriani (WMF), CC BY-SA 2.5
{kind=link}
Praxis mit Deployment
Führen Sie auf der Kommandozeile git clone git@gitlab.rlp.net:studiengang-digitale-methodik/modul-7/automated-deployment-example.git aus, um eine lokale Kopie der Übungsdateien anzulegen. Navigieren Sie dann in den neu entstandenen Ordner automated-deployment-example. Hier finden Sie die nötigen Dateien, mit denen Sie auf Ihrem Gerät ein automatisiertes Deployment mit dem Automatisierungswerkzeug Ansible ausführen können.

Grafik: Ansible als zentrales Deployment-Werkzeug
Sollten Sie aktive Docker-Container auf Ihrem Gerät laufen haben, die Port 80 verwenden, beenden Sie diese zunächst über Docker Desktop oder mit docker stop { Container-Name }.
Starten Sie dann den Deployment-Prozess, indem Sie im o.g. Ordner auf der Kommandozeile ./run ausführen. Sie erhalten nun fortlaufende Angaben über die gerade ausgeführten Schritte, bis der Prozess abgeschlossen ist. Da für die Testanwendung mehrere Docker-Images heruntergeladen werden und in den Containern zusätzliche Software installiert wird, kann dies eine Weile dauern (je nachdem, was für ein Gerät verwendet wird, bis zu 15 Minuten).
Sobald der Deployment-Prozess abgeschlossen ist, werden Ihnen in Docker Desktop (oder mit docker ps auf der Kommandozeile) drei neue laufende Container angezeigt. Die Website der Testanwendung erreich Sie unter http://localhost/.
Aufgaben
- Schauen Sie sich die Datei
runim Ordnerautomated-deployment-examplean. Was passiert hier? - Ansible verwendet YAML-Dateien, sogenannte Playbooks, um automatisierte Prozesse zu beschreiben. Schauen Sie sich die Datei
deploy.ymlan und versuchen Sie, eine kurze natürlichsprachliche Beschreibung des dort konfigurierten Ablaufs zu erstellen. - Der Prozess, den Sie gerade ausgeführt haben, ist ein minimales Beispiel für automatisiertes Deployment und nicht auf einen optimalen Ablauf in einer Produktionsumgebung abgestimmt. Welche Probleme und Risiken würden Sie sehen, wenn man dieses Playbook für ein ’echtes’ Deployment verwenden würde? Wie könnte man diese ggf. beheben?
Weitere Informationen
Cloud- und „Serverless“-Computing
Cloud Computing
Bedingt durch die Fortschritte im Bereich der Virtualisierung Angebote, die unter dem Begriff Cloud Computing zusammengefasst werden, einen starken Wachstumsschub erhalten. Grundsätzlich beschreibt der Begriff die Bereitstellung von Infrastrukturen und Diensten (bspw. Speicherplatz, Rechenleistung oder spezifische Softwarepakete) nicht mehr in Form lokaler, dedizierter Instanzen sondern über ein Netzwerk. Im Falle von Webanwendungen stehen hier das World Wide Web und HTTP im Mittelpunkt.
In den letzten 10 Jahren ist ein Paradigmenwechsel erfolgt. Zum einen haben sich unzählige neue Firmen und Geschäftsmodelle entwickelt, die ihre (virtuellen) Produkte ausschließlich über das Web anbieten (bspw. Facebook, Dropbox, GitHub etc.). Zum anderen wird das Feld technologisch und konzeptionell sehr stark durch die Internetkonzerne geprägt, sodass es nicht viele “freie” Alternativen und Anbieter gibt. Die folgende Grafik gibt einen Überblick über Aspekte, die zum Bereich Cloud Computing gerechnet werden:

Grafik: Elemente des Cloud Computing
Quelle: Sam Johnston, CC BY-SA 3.0
{kind=link}
Für den Bereich Webanwendungen ist entscheidend, dass die traditionellen Formen des Deployments und Hostings webbasierter Anwendungen auf dedizierten Serversystemen zunehmend verschwinden und durch Cloud-Lösungen ersetzt werden. Anstelle klassischer Webstacks treten gekoppelte, (häufig containerbasierte) virtuelle Architekturen, die über Microservices miteinander kommunizieren. Die bekanntesten Cloud Computing Plattformen, die für den Bereich Webanwendungen Bedeutung haben, sind aktuell:
Weitere Informationen
„Serverless“-Computing
Eine besonders aktuelle und für den Bereich Webanwendungen relevante Form des Cloud Computing ist das Serverless Computing. Da hierfür im Hintergrund immer noch Server benötigt werden, mit denen die Rechenkapazität bereitgestellt wird, ist der Begriff etwas irreführend. Eine bessere Bezeichnung für das Konzept lautet Functions as a Service (FaaS).
Kerngedanke von FaaS ist dabei, nicht mehr ganze Webanwendungen sondern lediglich Laufzeitumgebungen für Funktionen (in einer beliebigen Programmiersprache) cloudbasiert bereitzustellen. Diese Funktionen können über einen HTTP-Endpoint angesprochen und ausgeführt werden. So könnte eine (cloudbasierte) Funktion z.B. eine GND-Nummer entgegennehmen, diese über eine Schnittstelle auflösen und die erhaltenen Normdaten zurückliefern. Die benötigte Rechenkapazität für die Ausführung einer solchen Funktion wird bei FaaS dynamisch und automatisiert durch den Cloud-Anbieter bereitgestellt. Der/die Entwickler_in hat keinen weiteren Einfluss auf die Systemgegebenheiten. Viele Cloud-Anbieter unterstützen inzwischen weborientierte Sprachen und Frameworks (bspw. node.js, Python etc.).
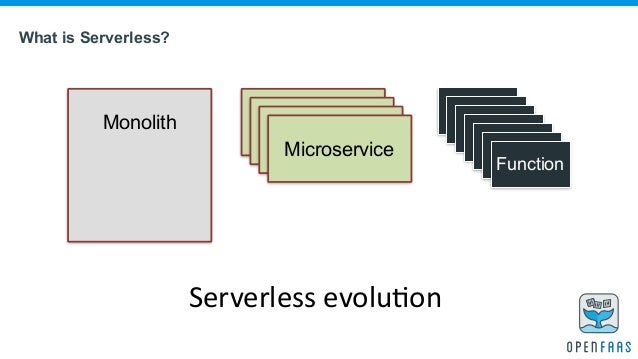
Grafik: Was ist Serverless Computing?
Quelle: Alex Ellis, FaaS-and-Furious
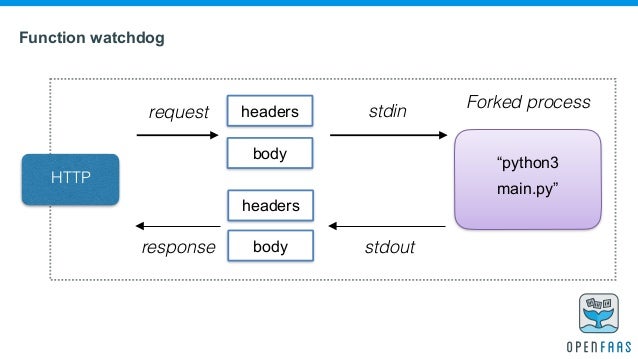
Grafik: Function as a Service
Quelle: Alex Ellis, FaaS-and-Furious