Ausblick und Machine Learning
Nun da wir unsere STURM-Webanwendung implementiert und uns die Hände mit einigen verschiedenen Technologien schmutzig gemacht haben, wenden wir uns noch der Metaperspektive auf Webentwicklung zu. Dabei gehen wir zunächst auf Möglichkeiten des Projektmanagements ein und betrachten dann das Thema Qualitätssicherung. Anschließend werfen wir noch einen kurzen Blick auf die Critical Code Studies.
Danach gehen wir zum Thema Machine Learning (ML) und Large Language Models (LLMs) über, die unter dem Buzzword „KI“ bzw. „Künstliche Intelligenz“ die aktuelle große Investmentblase internationaler Technologieunternehmen und Venture Capital-Fonds befeuern. Auch für Förderlinien für Projekte in den deutschen Geistes- und Kulturwissenschaften gewinnt dieses Thema zur Zeit noch an Bedeutung.
Vorgehensmodelle zur Softwareentwicklung
Die Entwicklung von Software ist ein potenziell unübersichtlicher Prozess. So kann es für neue Teammitglieder schwierig sein, sich in eine vorhandene Codebase einzuarbeiten, wie Sie womöglich im bisherigen Verlauf des Moduls gesehen haben. Zudem arbeiten in Technologieunternehmen und auch Webagenturen oder Technik- und Forschungsabteilungen mit Digital Humanities-Schwerpunkt häufig verteilte Teams mit einer Mischung aus Remote- und Präsenzarbeit. Verschärft wird das von einer sich stetig wandelnden Technologielandschaft, die es erfordert, sich regelmäßig fortzubilden und die eigenen Anwendungen sorgsam zu maintainen, also benutzbar zu halten.
Neben dem Arbeitsumfeld stellen auch die zu Beginn eines Entwicklungsprozesses sowie in dessen Verlauf tendenziell unklaren Anforderungen eine Herausforderung dar. Oft genug herrscht bei der Entwicklung von Software nicht einmal Einigkeit darüber, wer genau die Stake Holder der Anwendung tatsächlich sind und wer von Ihnen Entscheidungen treffen kann, sollte oder darf.
Um dem zu begegnen haben sich verschiedene Vorgehensmodelle etabliert, die hier kurz anhand dreier exemplarischer Grafiken gegenübergestellt werden sollen. Die Modelle teilen die Entwicklung von Software in verschiedene Phasen auf und setzen sie in Bezug zu einander. Als Modelle treten sie in der Regel nicht in Reinform auf, auch weil verteilte Teams nur sehr selten über lange Zeit mit derselben, eingespielten Belegschaft arbeiten können oder wollen.
Wassefallmodell
Beim Wasserfallmodell wir der Entwicklungsprozess einmalig und mit klar abgestuften Phasen bis hin zum fertigen Produkt durchlaufen. Das Modell endet in einem Wartungsmodus, in dem die Software weiter vertrieben werden kann ohne dass dieselbe Menge Ressourcen (Geld) hineingesteckt werden muss wie während des Hauptprozesses.
Dieses Entwicklungsmodell ist anfällig für fehlerhafte, komplexe oder unvollständige Anforderungslisten (Lastenhefte) zu Beginn, die die folgenden Phasen negativ beeinflussen. Außerdem sieht das Modell keine Reaktion auf sich im Verlauf eines Software-Lebenszyklus ändernde Anforderungen vor.

Grafik: Wasserfallmodel nach Paul Hoadley, Paul Smith and Shmuel Csaba Otto Traian
{kind=link}
V-Modell
Wie das Wasserfallmodell organisiert auch das V-Modell die Softwareentwicklung in klar abgegrenzte Phasen. Die größte Änderung liegt in der Gegenüberstellung der Entwicklungsphasen mit Prozessen zur Qualitätssicherung. In der ersten Hälfte bewegt sich das Projekt dabei von einer groben Analyse der Anforderungen bis hin zu einem sehr detaillierten Entwurf. In der zweiten Phase werden verschiedene Tests eingesetzt, um vom kleinen Detail bis hin zur groben Draufschau mögliche Probleme aufzuspüren und zu vermeiden.
Auch dieses Modell geht von einer Investment- und einer Profitphase von Software aus. Obwohl die Qualitätssicherung hier explizit mitgedacht wird, um möglichst genau auf vorher vereinbarte Anforderungen zu passen, kann es dazu kommen, dass z.B. Architekturprobleme in späten Phasen nur noch mit Workarounds gelöst werden statt die Architektur in einer solch späten Projektphase noch einmal zu ändern.

Grafik: V-Modell nach VDI/VDE 2206 von 2021
Quelle: Wikipedia, Verein Deutscher Ingenieure (VDI), CC0 1.0
{kind=link}
Spiralmodell
Im Gegensatz zu den zwei vorigen Vorgehensmodellen ist das Spiralmodell dezidiert iterativ gedacht indem es sich wiederholende Phasen vorsieht. Die Entwicklung einer Software durchläuft dabei immer wieder die vier Phasen Zielfestlegung, Risikoanalyse, Entwicklung/Test und Planung. Entwicklungsschritte sollen dabei in kleine Häppchen unterteilt werden bis die Software einen erwünschten Stand erreicht hat.
Die kleinen Ziele werden von Zyklus zu Zyklus festgelegt, wobei zwar ggf. durch jeden Zyklus die Kosten steigen, doch wird das Produkt idealerweise passgenauer und kann auf sich ändernde Anforderungen eingehen. Am Ende kann entweder ein fertiges Produkt stehen, das in periodischen Zyklen weiter gewartet wird, oder auch die Weiterentwicklung hin zu größerem Funktionsumfang. Im oft von befristeten Fördermitteln oder ebenso befristeten Phasen der Prestigesuche abhängigen Geschäft der Digital Humanities ist dieses Modell ggf. schwer umzusetzen, wird aber unter Umständen als Ideal propagiert.

Grafik: Spiralmodell nach Barry W. Boehm (1986)
{kind=link}
Weitere Informationen
Entwicklungsprozesse
Basierend auf diesen Vorgehensmodellen haben sich verschiedene Entwicklungsprozesse etabliert, die von Organisation zu Organisation und manchmal auch von Projektteam zu Projektteam unterschiedlich strikt umgesetzt werden. Inbesondere um den oft als schwerfällig empfundenen Prozessen des Wasserfall- und des V-Modells entgegenzuwirken, setzt z.B. die Agile Softwareentwicklung auf das iterative Vorgehen des Spiralmodells.
Ziel ist die schnelle Produktion einer funktionierenden Software bis hin zum Minimum Viable Product (MVP). In möglichst kurzen Reflexionsphasen zum Ende des einen und zum Beginn des nächsten Sprints wird sowohl der Funktionsumfang erweitert also auch (idealerweise) der Bedarf für Architekturänderungen berücksichtigt und eingeplant.
Als Beispiel für einen agilen Entwicklungsprozess kann der Blick auf die aktuelle Browserlandschaft dienen. Während noch vor einigen Jahren oft Jahre zwischen großen Hauptversionen mit entsprechend großen Veränderungen lagen, so zielen Browserhersteller heute oft auf vierwöchige Releasezyklen ab, die jeweils kleine Änderungen mit sich bringen aber sich beispielsweise auf ein Jahr gerechnet summieren.
Die größte Herausforderung für die agile Entwicklung stellen große Architekturänderungen sowie die Veränderung komplexer Abhängigkeiten in den verbauten Komponenten dar. Diese Prozesse müssen oft parallel zum alten Produkt gehalten werden, weil sie nicht in die kurzen Zyklen passen. Weitere Entwicklungsprozesse, die oft ähnliche Ziele verfolgen, sind Kanban, Extreme Programming und Scrum. Letzteres benennt pro Zyklus oder pro Team klare Rollen, um die reibungsarme Zusammenarbeit und kritische Reflexion der eigenen Arbeit zu fördern.
Praxis zu Entwicklungsprozessen
Wir informieren uns über die wichtigsten Kernkonzepte von Scrum und tauschen uns in der Gruppe dazu aus:
- Welche Rollen legt Scrum fest?
- Wie lassen sich diese Rollen mit unseren Erfahrungen im Kurs vereinbaren?
- Wie hätten wir unsere Arbeit nach Scrum umorganisieren müssen?
- Welche Vor- und Nachteile sehen wir dafür in unserem eigenen Lernprozess?
- Wie beurteilen wir Scrum als Methode für die Berufswelt?
Qualitätssicherung für Webanwendungen
In den meisten aktuell eingesetzten Vorgehensmodellen spielt die Qualitätssicherung für Software eine Rolle. Dies geschieht meist mit Hilfe von Softwaretests und deren möglicher Automation:
Ein Softwaretest prüft und bewertet Software auf Erfüllung der für ihren Einsatz definierten Anforderungen und misst ihre Qualität. Die gewonnenen Erkenntnisse werden zur Erkennung und Behebung von Softwarefehlern genutzt. Tests während der Softwareentwicklung dienen dazu, die Software möglichst fehlerfrei in Betrieb zu nehmen. - Wikipedia
Im Bereich Webanwendungen kommen häufig Akzeptanztests zum Einsatz. Diese entscheiden während einer Continuous Integration (CI), also dem kontinuierlichen Aufnehmen von Änderungen in ein zentrales Repositorium, über die Annahme- oder Nicht-Annahme der Änderung. Auch wenn die Änderung aufgenommen wird zeigen die Tests idealerweise an, welche Stellen im Code nachgebessert werden müssen, um die festgelegten Qualitätskriterien zu erfüllen. Eine gute Übersicht über mögliche Testformen bietet der OWASP Web Security Testing Guide:
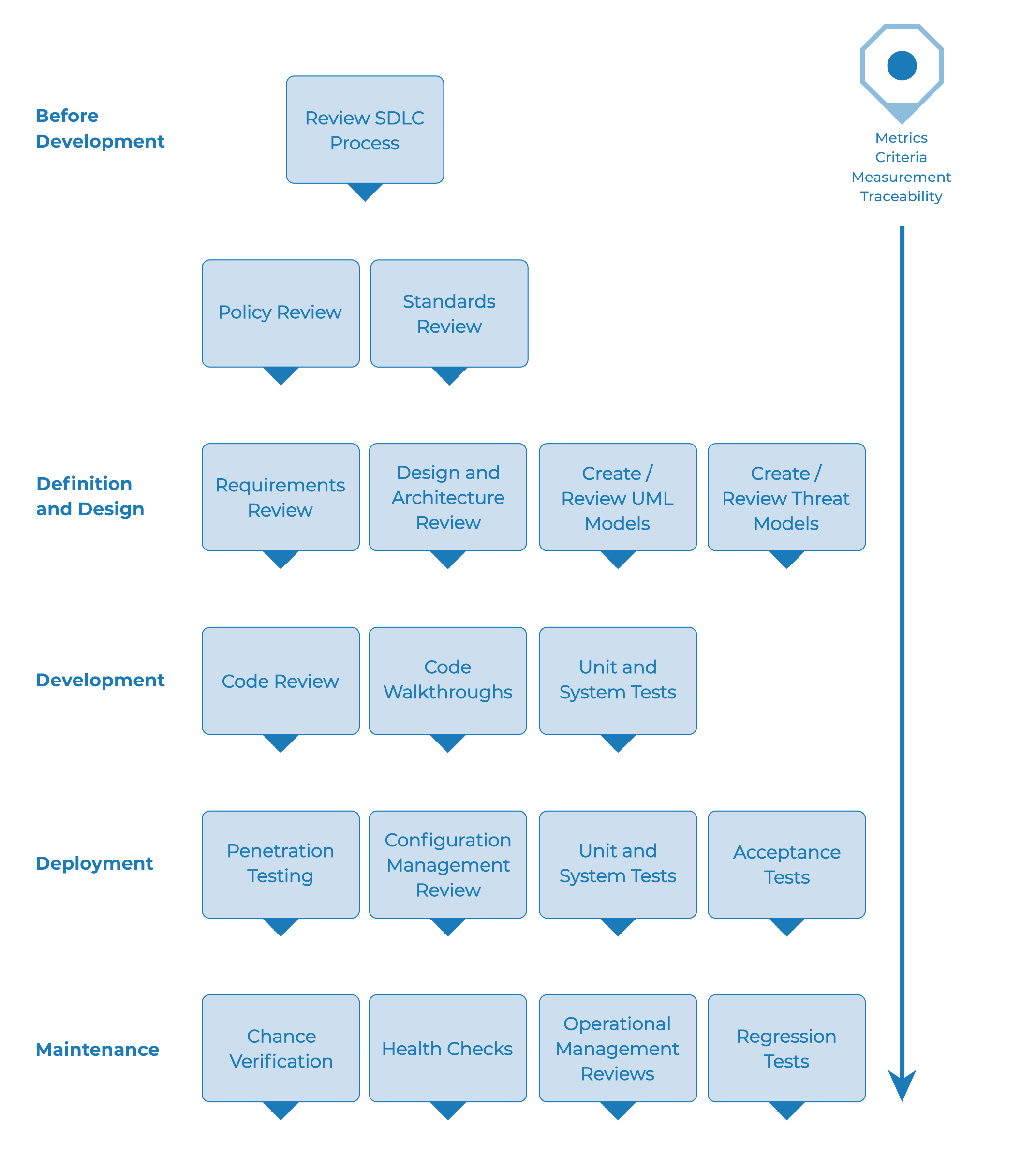
Grafik: A Typical SDLC Testing Workflow
Quelle: OWASP Web Security Testing Guide, CC BY-SA
Weitere Informationen
- Präsentation mit einem Überblick über die Arten von Softwaretests
- TheJambo, Awesome Testing
- OWASP Web Security Testing Guide
- ISO/IEC/IEEE 29119, International Standard — Software and systems engineering — Software testing
- Tim A. Majchrzak, Herbert Kuchen, Softwaretests. Working Paper No. 2, Förderkreis der Angewandten Informatik an der Westfälischen Wilhelms-Universität Münster e.V.
- Florian Ehmke, Softwaretests, 2011
- Jan Peleska, Verbesserte Softwarequalität durch effiziente Testprozesse, TZI und Verified Systems International GmbH
Behaviour-Driven Development
Beim Behaviour-Driven Development (BDD) lässt sich die Präsentationsschicht einer Webanwendung anhand von Kriterien testen:
- BDD beschreibt die Funktionalität einer Anwendungsdomäne mittels formalisierter Szenarien.
- BDD ist ein “outside-in”-Ansatz, der mit dem Blick der Nutzer:innen auf eine Forschungssoftware blickt und deren Funktionalität in ausführbaren Tests dokumentiert.
- Die Tests werden in natürlicher Sprache nach einem festen Dreischritt-Prinzip formuliert.
- Dadurch kann die Präsentationsschicht einer Software z.B. auch in Zusammenarbeit mit Fachwissenschaftler:innen gemeinsam beschrieben und nachhaltig dokumentiert werden.
Als Framework für diese Art von Tests lässt sich das Framework Behat einsetzen. Behat ermöglicht die Beschreibung von Funktionen (features) einer Software bzw. Webanwendung mittels natürlicher (formalisierter) Sprache. Features sind dabei in einzelne Szenarien (scenarios) untergliedert.
Weitere Informationen
Critical Code Studies
Die Critical Code Studies sind eine wichtige, aber noch im Entstehen befindliche Disziplin an der Nahtstelle zwischen Digital Humanities, Kulturwissenschaften und Computer Science. Die Grundidee ist die Anwendung der Kritischen Theorie (nicht nur im Sinne der Frankfurter Schule sondern entsprechend ihrer anglophonen, breiteren Auslegung als Critical Theory) auf Software und deren Code anzuwenden.
Dabei wird davon ausgegangen, dass nicht einmal eine einzelne Zeile Code „neutral“ formuliert sein kann, weil sie immer auf Grundannahmen, Anforderungen durch Programmiersprachen und weitere Akteure oder z.B. auch Weltanschauungen fußen. Auch grafische Oberflächen oder technische Infrastrukturen wie GitHub oder Cloudanbieter, die in der aktuellen Softwareentwicklung eine wichtige Rolle spielen, können mit diesem Ansatz analysiert und kritisch betrachtet werden.
Praxis mit Critical Code Studies
Lassen Sie uns einzeln oder als Gruppe einen geeigneten Untersuchungsgegenstand aus der Perspektive der Critical Code Studies überlegen. Als Einstieg kann die visuelle und inhaltliche Analyse einzelner Web- oder auch App-Oberflächen hilfreich sein, wie z.B.
Nach einer solchen wortwörtlich oberflächlichen Analyse sollten wir aus unseren Erkenntnissen weitere Fragen entwickeln und dabei reflektieren, wo uns diese hinführen und warum. Ebenfalls wichtig: Unter welchen Bedingungen kann uns die Untersuchung auch in den Quellcode führen?
Künstliche Intelligenz und Machine Learning
Spätestens seit der Möglichkeit, Large Language Models wie ChatGPT über eine einfache Weboberfläche zu nutzen, ist klar, dass künstliche Intelligenz und Machine Learning in vielen Bereichen eine wichtige Rolle spielen wird. Dies gilt auch für die Softwareentwicklung im Zusammenhang mit den Digital Humanities.
KI als Entwicklungswerkzeug
Viele von Ihnen haben im Lauf des Moduls vermutlich bereits KI zur Unterstützung beim Lernen und Programmieren verwendet (Sie wurden in diesem Handbuch sogar explizit dazu ermutigt). Dabei haben Sie möglicherweise auch schon festgestellt, dass die KI Ihnen nicht immer ganz korrekte Antworten gegeben hat, oder Antworten, die nicht wirklich zu Ihrer beabsichtigten Frage passten.
Das liegt zum einen daran, dass KIs wie ChatGPT anders als menschliche Gesprächspartner nicht nachfragen, wenn die gestellte Frage mehrdeutig oder unklar ist. Zum anderen liegt es aber auch daran, dass diese Modelle mit Daten aus dem Internet trainiert wurden und es auch hier zu bestimmten Themen eine Menge mehrdeutige oder falsche Informationen gibt, die das Modell als Ausgangsmaterial für seine Antworten verwendet. Ohne eigene Fachkenntnis kann man hier schnell auf falsche Fährten geraten. KI als Co-Programmierer:in einzusetzen lohnt sich also (derzeit zumindest noch) erst wirklich, sobald man selbst robuste Grundkenntnisse zu einer Programmiersprache hat.
Dann kann KI aber durchaus ein nützliches Werkzeug sein und wird als solches auch bereits für professionellen Einsatz angeboten. GitHub Copilot ist ein aktuelles Beispiel für die Verwendung von KI als Entwicklungswerkzeug. Hier kann die OpenAI-Codex-API über das Copilot-Plugin für verschiedene IDEs direkt in den Entwicklungsprozess eingebunden werden und während des Programmierens Vorschläge für Code-Snippets machen. Auch wenn die Qualität der Vorschläge noch nicht immer überzeugend ist, kann hiermit generell Zeit eingespart werden.

Screenshot: GitHub Copilot in Sublime Text 3
Quelle: Frodo Podschwadek
Weitere Informationen
- Phil Price, ChatGPT4 writes Stan code so I don’t have to, https://statmodeling.stat.columbia.edu/2023/04/18/chatgpt4-writes-stan-code-so-i-dont-have-to/
- Rizel Scarlett, 8 things you didn’t know you could do with GitHub Copilot https://github.blog/2022-09-14-8-things-you-didnt-know-you-could-do-with-github-copilot/
- OpenAI Codex, https://openai.com/blog/openai-codex
KI als Anwendungsbestandteil
Künstliche Intelligenz kann auch als Teil einer Webandwendung verwendet werden. Die Browser-UIs der großen LLMs von OpenAI, Microsoft und Google sind letztlich Webandwendungen, die mit den dahinterliegenden komplexen Anwendungsmodulen interagieren. Machine-Learning-Modelle verschiedener Komplexität können jedoch auch auf unterschiedlichen Wegen in eigene Webanwendungen integriert werden.
APIs
Die derzeit einfachste Möglichkeit ist, die API eines dieser Anbieter zu nutzen. OpenAI bietet zum Beispiel eine ausführlich dokumentierte API an, die im Grunde den gleichen Leistungsumfang hat wie die Weboberfläche.
Aber auch wenn diese Art, künstliche Intelligenz in eine Webanwendung einzubinden, wohl zu den bequemsten gehört, müssen vorher zumindest zwei wichtige Faktoren bedacht werden: Kosten und Datenschutz. Die Nutzung kommerzieller APIs ist mit Kosten verbunden, die vom Umfang der gesendeten Anfragen abhängen. Während dies im Rahmen kommerzieller Webanwendungen, mit denen selbst Umsatz generiert wird, in der Regel kein Problem ist, stellen solche Preismodelle z.B. für Forschungsprojekte mit einem begrenzten, von vornherein festgelegten Budget i.d.R. ein Ausschlußkriterium dar. Doch selbst wenn das erforderliche Budget verfügbar ist, sollte der Datenschutz nicht vergessen werden. Je nach Art der Anwendung ist es möglich, das personenbezogene oder sonstige sensible Daten in die API eingespeist werden. Da die Verarbeitung der Daten in dem meisten Fällen außerhalb der Europäischen Union stattfindet, kann es zu Konflikten mit dem Vorgaben der GPDR bzw. der DS-GVO kommen.
Praxis mit Künstlicher Intelligenz: Über eine API
Der Dienstleister DeepL bietet neben einer Weboberfläche auch eine API für maschinelle Übersetzungen an. Mit Ihren bisher erworbenen Kenntnissen im Umgang mit PHP und mit APIs können Sie bereits ein einfaches PHP-Programm schreiben, dass bei der DeepL-API über den Endpoint
https://api-free.deepl.com/v2/translate
eine Übersetzung für den folgenden Text anfordert:
Dies ist eine Anfrage aus dem Studiengang Digitale Methodik in den Geistes- und Kulturwissenschaften.
Verwenden Sie dafür das bereits aus dem Kapitel “HTTP, APIs und Datenformate” bekannte Image für einen einfachen PHP-HTTP-Client. Legen Sie sich einen neuen Ordner an, in dem die Datei mit Ihrem PHP-Programm liegen wird und erstellen sie aus diesem Ordner heraus einen Container:
docker run -dit -v ./:/opt/app -w /opt/app --name http-client --rm registry.gitlab.rlp.net/studiengang-digitale-methodik/modul-7/php-http-client-base
Nutzen Sie das bereits im Container vorinstallierte Guzzle-Paket, um einen entsprechenden Request an die DeepL-API zu schicken und den Inhalt der Response mit PHP darzustellen. Sie benötigen folgende zusätzliche Informationen:
- Die Request-Dokumentation für Guzzle: https://docs.guzzlephp.org/en/stable/request-options.html
- Die API-Dokumentation von DeepL: https://developers.deepl.com/docs/getting-started/auth und https://developers.deepl.com/docs/getting-started/your-first-api-request
- Einen Autorisierungsschlüssel:
63050bd6-fbbb-635a-529a-8ceebded4666:fx
Hinweis
Wenn Sie experimentieren wollen, können Sie im Client-Container mit Composer das offizielle DeepL-Composer-Paket installieren und dieses verwenden:
Bedenken Sie dabei, dass das so installierte Paket nur im Container persistiert, solange dieser nicht mit docker remove bzw. über das entsprechende Symbol in Docker desktop komplett entfernt wird. start und stop lassen den Container und seine Inhalte hingegen intakt.
Container
Eine weitere Möglichkeit, künstliche Intelligenz in Webanwendungen zu integrieren, ist, sie in Containern laufen zu lassen. Dafür eignen sich vor allem sogenannte Transformer-Modelle, die verhältnismäßig einfach und leistungsstark zugleich sind. Seit der Veröffentlichung des ersten Forschungsartikels zu den technischen Grundlagen von Transformern (siehe Vasvani et al 2017) haben diese Machine-Learning-Modelle rapide an Populariät gewonnen. Ähnlich wie die Paket-Ökosysteme npm und packagist für JavaScript bzw. PHP, gibt es inzwischen auch Repositorien für Transformer-Modelle, die Modelle und Datensets für unterschiedliche Zwecke (und unterschiedlicher Qualität) zur Verfügung stellen und so Verwendung dieser Modelle in Webanwendungen vereinfacht.
Ein solches Repositorium ist Huggingface Transformers. Hier findet sich eine vielzahl von Modellen, die bereits für unterschiedlichste Aufgaben trainiert wurden und direkt eingesetzt werden können. Die hier zu findenden Modelle sind primär für die Verwendung in verschiedenen Machine-Learning-Frameworks in Python konstruiert. Über eine containerisierte Einbettung in einer Docker-Anwendung ist es verhältnismäßig einfach, eine Webanwendung zu entwickeln, die (a) einen der bekannten Stacks verwendet und die (b) über das interne Docker-Netzwerk Zugriff auf das entsprechende Modell in einem eigenen Python-Container hat.
Frontend-JavaScript
Noch einfacher ist die Verwendung von Transformers.js, das JavaScript statt Python verwendet. Hier laufen die Modelle auf einem Node.js-Server oder sogar direkt im Browser. In letzterem Fall muss beim Design der Anwendung allerdings bedacht werden, wie viel Rechenlast auf den Client ausgelagert werden soll. Für Nutzer:innen mit weniger starken Endgeräten oder langsamer Internetverbindung kann dies ansonsten schnell dazu führen, dass die Webanwendung unkomfortabel oder gar nicht mehr nutzbar wird.

Screenshot: Objekterkennung mit einem Transformer-Modell im Browser
Quelle: Frodo Podschwadek
Praxis mit Künstlicher Intelligenz: Im Browser
Klonen Sie sich das Repositorium mit den Dateien für die Übungsanwendung mit
git clone git@gitlab.rlp.net:studiengang-digitale-methodik/modul-7/object-recognition-app
und starten Sie die Anwendung mit
docker run -d -p 80:80 -v ./object-recognition-app:/var/www/html --name ai-app --rm jitesoft/lighttpd
Unter http://localhost/ erreichen Sie nun eine Anwendung zur Objekterkennung in Bildern. Sie können nun beliebige Bilder laden und analysieren.
Aufgaben:
- Schauen Sie sich die Datein im Anwendungsordner
object-recognition-appan und erstellen Sie eine natürlichsprachliche Beschreibung des Programmablaufs. - Welche Codeabschnitte sind für die Objekterkennung zuständig?
- Überlegen Sie sich, welche Anwendungsfälle es für einen Objekt-Erkennungs-Anwendung wie diese (ein spezialisiertes Training des Modells vorausgesetzt) in für Webanwendungen es im Bereich der Digital Humanities geben könnte. Versuchen Sie, mindestens drei potentielle Anwendungsfälle zu skizzieren.