HTTP, APIs und Datenformate
Dieses Kapitel behandelt die Grundlagen der Kommunikation im Internet mit dem Hypertext Transfer Protocol (HTTP). Darüber hinaus vermittelt es einen Überblick über verschiedene Schnittstellen (APIs) und einige Datenformate, die in diesem Zusammenhang verwendet werden (z.B. JSON und XML).
Der praktische Teil des Kapitels beschäftigt sich mit der Analyse von Requests und Responses, die mit unterschiedlichen Formaten arbeiten.
Geschichte
Die Geschichte von HTTP beginnt im Jahr 1989. Zu dieser Zeit arbeitete Sir Tim Berners-Lee als Physiker am CERN. Mit seinem Vorschlag “Information Management, A Proposal” legte Berners-Lee (zunächst noch unter dem Arbeitstitel “Mesh”) die konzeptionellen Grundlagen für das, was wir heute als World Wide Web kennen.
Grafik: Originaldarstellung des Mesh (Berners-Lee 1989)
Zwischen März 1989 und August 1991 erarbeiteten Berners-Lee und ein Team von Forschern die Spezifikationen und Beispielimplementierungen für die vier grundlegenden Säulen des Web:
- Das Hypertext Transfer Protokoll (HTTP), ein einfaches Protokoll zur Übertragung von Daten in einem Rechnernetz.
- Die Hypertext Markup Language (HTML), ein textuelles Auszeichnungsformat für Hypertext-Dokumente, die über HTTP übertragen werden.
- Den ersten Webserver ("httpd"), der Zugriff auf in HTML ausgezeichnete Hypertext-Dokumente in einem Rechnernetz erlaubte.
- Den ersten Browser ("WorldWideWeb"), der diese HTML-Dokumente bei einem Webserver anfragen und nach Empfang darstellen konnte.
Die öffentliche Verfügbarmachung der HTTP-Spezifikation und der dazugehörigen Referenzimplementierungen hat maßgeblich dazu beigetragten, dass sich die in den Jahren 1989–1991 grundgelegten Konzepte weltweit durchsetzten.
Weitere Informationen
HTTP (Hypertext Transfer Protocol)
“HTTP ist ein zustandsloses Protokoll zur Übertragung von Daten auf der Anwendungsschicht über ein Rechnernetz. Es wird hauptsächlich eingesetzt, um Webseiten (Hypertext-Dokumente) aus dem World Wide Web (WWW) in einen Webbrowser zu laden. Es ist jedoch nicht prinzipiell darauf beschränkt und auch als allgemeines Dateiübertragungsprotokoll sehr verbreitet.” (Quelle: Wikipedia)
Die Kommunikation über HTTP erfolgt client-server basiert. Als Transportschicht für die Kommunikation kommt TCP/IP (Transmission Control Protocol/Internet Protocol) zum Einsatz. Innerhalb des OSI Referenzmodells für die Einordnung von Netzwerkprotokollen befindet sich HTTP auf Ebene 7 (der Anwendungsschicht).

Grafik: Open Systems Interconnection Model
Quelle: Torsten Schrade
Zu den Grundkonzepten von HTTP gehören die Anfrage (Request) des Client, die Antwort (Response) des Servers, Uniform Resource Identifiers (URIs) zur Adressierung der Ressourcen sowie eine einfache Nachrichtenstruktur.
Client und Server tauschen innerhalb eines HTTP-Request-Response-Zyklus Nachrichten aus. Handelt es sich beim Client um einen Webbrowser, kommen häufig weitere Technologien (bspw. CSS und JavaScript) zum Einsatz, um die Nachrichten (bspw. die HTML-Dokumente) in adäquater Form darzustellen oder zusätzliche Funktionalitäten anzubieten.

Grafik: Bausteine des World Wide Web
Quelle: Torsten Schrade
URIs und URLs
Das Ziel einer HTTP-Anfrage ist immer eine Ressource. Eine Ressource ist hierbei ein abstraktes Konzept und kann für unterschiedliche Dinge stehen - bspw. ein HTML-Dokument, ein Bild, ein Film oder - im Sinne des Semantic Web - ein “Ding” in der Welt, zu dem Informationen existieren (bspw. eine Person, ein Ort, aber auch ein Konzept etc.).
Jede Ressource hat mindestens einen global eindeutigen Identifikator, der sie von anderen Ressourcen unterscheidet. Dieser Identifikator ist der Uniform Resource Identifier (URI). Der Identifikator einer Ressource und der Ort, an dem sich die konkrete Ressource befindet, müssen dabei nicht notwendigerweise übereinstimmen. Hierin liegt der Unterschied zwischen einem URI und dem Uniform Resource Locator (URL), der einen “Zeiger” auf den konkreten Ort einer Ressource darstellt.
HTTP verwendet zur Identifikation von Ressourcen URIs. Häufig fallen dabei die Identität und der Ort einer Ressource, also URI und URL, zusammen. Der Vorteil ist, dass HTTP-URIs über das Domain Name System (DNS) direkt aufgelöst werden können. Es ist also möglich, mittels einer HTTP-URI direkt zur Ressource bzw. einer Repräsentation der Ressource (bspw. in Form eines HTML-, XML- oder JSON-Dokumentes) zu gelangen.
HTTP-URIs haben eine standardisierte Syntax und bestehen aus den folgenden Komponenten:

Grafik: Bestandteile eines URI
Quelle: Torsten Schrade
Scheme
Das Schema beschreibt den Typ einer URI. Als Schemas können sowohl standardisierte Protokolle (wie bspw. “http” oder “ftp”) als auch anwendungsspezifische Protokolle (wie bspw. “git” oder “ssh”) oder auch Namensräume (bspw. “urn” oder “doi”) verwendet werden. Die Schema-Angabe wird durch einen Doppelpunkt (:) beendet. Das Schema ist ein obligatorischer Bestandteil eines URI.
Authority
Die Authority beschreibt die Instanz, welche die Namen in dem vom Schema angegeben Interpretationsraum verwaltet. Bei HTTP-URIs erfolgt dies im Rahmen des Domain Name Systems (DNS), das von Registraren verwaltet wird. Eine vollständige HTTP-Authority-Angabe besteht aus Nutzername:Passwort:Host:Port. Hierbei sind die Elemente Nutzername, Passwort und Port optional. Die Host-Angabe kann entweder eine IP-Adresse, eine IPv6-Adresse oder ein registrierter Domainname sein. Die Authority wird durch zwei Schrägstriche (//) eingeleitet und durch einen Schrägstrich (/), ein Fragezeichen (?) oder ein Doppelkreuz (#) beendet. Die Authority ist ein optionaler Bestandteil eines URI.
Path
Beim Pfad handelt es sich im Zusammenspiel mit dem Query um den Bestandteil eines URI, der die jeweilige Ressource eindeutig identifiziert. Er kann unterschiedlich organisiert sein. Eine Möglichkeit ist eine an ein Dateisystem angelehnte hierarchische Form ("/pfad/zur/ressource"). Genauso gültig sind aber Pfadkomponenten, die durch Doppelpunkte abgetrennt werden (“teil:eines:urn”). Der Pfad wird von einem Fragezeichen (?), Doppelkreuz (#) oder dem Ende des URI begrenzt und ist ein obligatorischer Bestandteil eines URI.
Query
Der Abfrageteil eines URI wird durch ein (?) eingeleitet und enthält Daten zur Identifizierung einer Ressource, die nicht allein durch den Pfad ausgedrückt werden (bspw. wenn die Ressource aus einer Datenbank abgerufen wird). Eine Query setzt sich aus einem oder mehreren Schlüssel=Wert Paaren zusammen, die durch ein Ampersand (&) miteinander verbunden werden. Der Abfrageteil eines URI ist optional und wird entweder durch das Doppelkreuz (#) oder das Ende des URI begrenzt. Der Abfrage-Teil eines HTTP-URI kann dazu verwendet werden, um Daten zu dieser Ressource über die Request-Methoden GET und POST an den Server zu übertragen.
Fragment
Der Fragmentenbezeichner referenziert eine spezifische Stelle innerhalb einer Ressource. Er bezieht sich immer auf den jeweiligen URI und ist immer das letzte (optionale) Element eines URI.
URI vs. URN vs. URL
Häufig fällt die Unterscheidung zwischen URIs, URNs und URLs nicht leicht. Bei Uniform Resource Identifiern (URIs) handelt es sich um global eindeutige Identifikatoren für Ressourcen. Bei URNs und URLs handelt es sich um spezifische (Unter-)typen von URIs. Ein Uniform Resource Name (URN) ist ein URI nach dem Schema “urn”, der einer Ressource einen dauerhaften, ortsunabhängigen Namen gibt. Der Uniform Resource Locator (URL) wiederum beschreibt den Ort einer Ressource eindeutig.
Eine URN sagt aus, um wen oder was es sich handelt, während eine URL sagt, wo (an welchem Ort) sich das Objekt (die Ressource) befindet. Quelle: Wikipedia
Da URNs ortsunabhängige Namen für Ressourcen sind, können sie nicht direkt aufgerufen werden. Sie müssen erst in URLs oder URIs übersetzt werden.
Praxis mit HTTP (Vorbereitung)
Für die Praxiübungen zu HTTP und APIs benötigen Sie einen REST-Client, mit dem Sie unterschiedliche Request-Typen an einen Server senden und z.B. Header-Daten gezielt setzen können.
Wenn sie ein Add-On für Ihren Browser verwenden möchten, installieren Sie sich die RESTer-Extension, der eine komfortable Formularoberfläche für das senden von HTTP Requests an API-Endpunkte bietet (auch für Chrome erhältlich).
Falls Sie lieber eine freistehende Anwendung verwenden möchten, können Sie stattdessen auch Postman oder Insomnia installieren.
Nehmen Sie sich ausreichend Zeit, um sich mit dem von Ihnen gewählten Tool vertraut zu machen. Stimmen Sie sich ggf. mit Ihren Teammitgliedern ab, ob Sie jeweils unterschiedliche REST-Clients installieren und anschließend vergleichen wollen.
Weitere Informationen
Der Request-Response-Zyklus
Der Nachrichtenfluss über HTTP erfolgt in folgenden Schritten:
- Der Client öffnet eine Verbindung (über TCP/IP).
- Der Client sendet eine HTTP-Nachricht (Request) an einen Server.
- Der Server empfängt die Nachricht und verarbeitet sie.
- Der Server sendet eine HTTP-Nachricht an den Client (Response).
- Der Client empfängt die Nachricht und verarbeitet sie.
- Die Verbindung wird geschlossen. Je nach Protokoll-Version unterscheidet sich, welche Seite die Verbindung schliesst: In HTTP/1.0 ist dies der Server, in HTTP/1.1 ist die Verbindung i.d.R. persistent und bleibt offen, bis der Client sie schließt.

Grafik: HTTP-Request-Response-Zyklus
Quelle: Adora Nwodo, https://adorahack.com/http-request-methods-for-beginners
Ein Request-Response-Zyklus ist immer abgeschlossen und somit zustandslos. Es gibt zwischen mehreren Request-Response-Zyklen keinen kontinuierlichen Datenstrom.
Wird HTTP/1.1 verwendet, kann die Verbindung zwischen Client und Server für weitere Anfragen wiederverwendet bzw. offen gehalten werden. Dies ändert nichts an der Zustandslosigkeit eines Request-Response-Zyklus, ist jedoch effizienter.
Mit HTTP/2 können mehrere Anfragen in einem Request-Response-Zyklus zusammengefasst werden. Zudem sind die Nachrichten binär kodiert und nicht mehr direkt lesbar. HTTP/2 ist abwärtskompatibel zu HTTP/1.
HTTP-Nachrichten sind textbasiert und untergliedern sich in die Request-Nachricht (Anfrage, Client) und die Response-Nachricht (Antwort, Server). Eine HTTP-Nachricht enthält immer einen Nachrichtenkopf (Message Header) und einen Nachrichtenrumpf (Message Body) mit dem Nachrichteninhalt.

Grafik: Format einer HTTP-Nachricht
Quelle: Torsten Schrade
Da es sich bei HTTP um ein textbasiertes Protokoll handelt, können die Nachrichten auf allen an der HTTP-Kommunikation beteiligten Rechnern gelesen werden. Eine Verschlüsselung der Nachrichten kann im Rahmen einer Übertragung mittels HTTPS erfolgen. Hierbei wird eine zusätzliche Transportverschlüsselung zwischen HTTP und TCP/IP geschaltet. Die Verschlüsselung der Daten geschieht mittels SSL/TLS.
Weitere Informationen
Requests
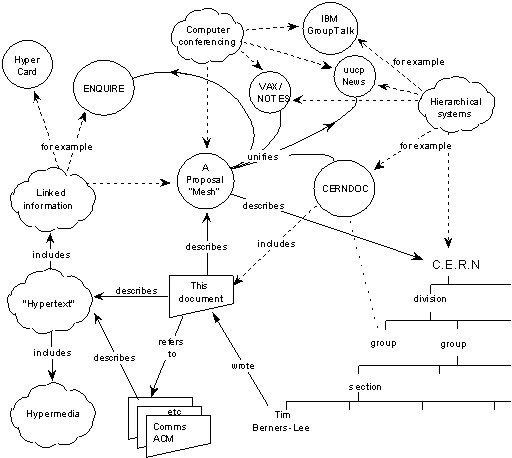
Ein HTTP-Request besteht aus folgenden verbindlichen Elementen: Der HTTP-Methode, dem Pfad zu der angefragten Ressource, der Protokoll-Version und (in HTTP/1.1) dem Hostname. Optional können in einem HTTP-Request zusätzliche Header sowie ein Body (Nachrichtenrumpf) an den Server gesendet werden.
Grafik: Bestandteile eines HTTP-Requests
Quelle: MDN, https://developer.mozilla.org/en-US/docs/Web/HTTP/Overview/http_request.png
Header
Der Client kann seinem HTTP-Request bestimmte Header mitgeben. Ein Header besteht dabei immer aus Schlüssel: Wert Paaren. Der Schlüssel beginnt dabei immer mit einem Großbuchstaben. Nachfolgend eine Übersicht über die wichtigsten Request-Header:
| Schlüsselwort | Werte (Beispiele) | Kurzbeschreibung |
|---|---|---|
Host |
de.wikipedia.org | |
Accept |
text/html | MIME Types |
Accept-Language |
en-GB | HTTP 1.1 Spezifikation |
Accept-Charset |
UTF8 | |
Accept-Encoding |
x-gzip | |
Connection |
Close/Keep-Alive | |
Referer |
https://www.wikipedia.org/ | |
User-Agent |
Mozilla/5.0 (Macintosh; Intel Mac OS X x.y; rv:42.0) Gecko/20100101 Firefox/42.0 | |
Content-Length |
3495 | |
Content-Type |
text/html | |
Cache-Control |
max-age=3600 | |
Authorization |
Basic YWxhZGRpbjpvcGVuc2VzYW1l | |
Cookie |
PHPSESSID=298zf09hf012fh2 | |
If-Modified-Since: |
Sun, 31 Dez 2017 07:28:00 GMT |
Weiterführende Informationen:
Methoden
Die HTTP-Spezifikation definiert die folgenden Request-Methoden, die von Clients für Anfragen an den Zielserver verwendet werden können. Die Request-Methode wird dabei in Großbuchstaben als erstes Element in der HTTP-Nachricht des Clients definiert. Die Request-Methode wird auch HTTP-Verb genannt. Nicht alle Webserver implementieren sämtliche Methoden der HTTP-Spezifikation. Andererseits können Server die Request-Methoden auch um eigene anwendungsspezifische Verben bzw. Funktionalitäten erweitern.
GET
Mittels GET fordert ein Client eine Ressource unter Angabe eines URI vom Server an. Eine GET-Anfrage darf dabei nur Daten abrufen und sonst keine Seiteneffekte erzeugen (wie bspw. eine Datenänderung auf dem Server). Je nach Server kann es eine maximale Länge für den angefragten URI geben (laut der Spezifikation 255 Bytes, gegenwärtig eher zwischen 2kb - 8kb). Die verschiedenen Clients und Server implementieren die maximale Länge eines URI unterschiedlich (Diskussion hierzu auf Stack Overflow).
GET /wiki/Digital_Humanities HTTP/1.1
Host: de.wikipedia.org
Accept: text/html
Accept-Language: de-DE
HEAD
Analog zur GET-Methode kann mittels HEAD eine Ressource auf einem Server angefragt werden. Bei Erfolg liefert der Server dabei aber keinen Nachrichtenrumpf sondern nur die Kopfdaten zurück. Da die Kopfdaten den Zeitstempel mit der letzten Aktualisierung der angefragten Ressource enthalten, kann der Client auf diese Weise prüfen, ob eine lokale Kopie der angefragten Ressource noch gültig ist oder mittels eines GET-Requests aktualisiert werden sollte.
HEAD /wiki/Digital_Humanities HTTP/1.1
Host: de.wikipedia.org
POST
Mittels POST kann eine (gemäß der Spezifikation unbegrenzte, in der Praxis je nach Serverimplementierung aber limitierte) Datenmenge an den Server übertragen werden. Der Nachrichtenrumpf enthält hierbei die zu übertragenden Daten. Im Falle eines HTML-Formulars, das über POST versendet wird, sind dies Name=Wert Paare. Wie der Server die eingehenden Daten verarbeitet ist nicht Bestandteil der Spezifikation (bspw. ob neue Ressourcen angelegt oder bestehende aktualisiert werden).
Nachrichtenrumpf als JSON:
POST /posts HTTP/1.1
Host: jsonplaceholder.typicode.com
Content-type: application/json
{
"userId": 99,
"id": 101,
"title": "Foo",
"body": "Bar"
}
PUT
Mit der PUT-Methode kann eine Ressource auf dem Server unter der angegebenen URI angelegt oder ersetzt werden. Existiert eine Ressource nicht, wird sie erstellt. Existiert sie bereits, wird sie ersetzt.
PUT /albums/1 HTTP/1.1
Host: jsonplaceholder.typicode.com
DELETE
Mit der DELETE-Methode kann eine Ressource auf dem Server unter der angegebenen URI gelöscht werden.
DELETE /albums/1 HTTP/1.1
Host: jsonplaceholder.typicode.com
TRACE
Die TRACE-Methode kann zur Fehleranalyse verwendet werden. Sie liefert die Anfrage so zurück, wie der Server sie empfangen hat. Da hierbei Systeminformationen nach außen gelangen wird diese Methode im Produktivbetrieb aus Sicherheitsgründen meistens deaktiviert.
OPTIONS
Mit der OPTIONS-Methode kann der Client den Server nach den verfügbaren Request-Methoden fragen. Dies ist im Rahmen von Web-APIs hilfreich um programmtechnisch zu erkennen, welche Aktionen am Einstiegspunkt einer Web-API verfügbar sind. Die verfügbaren Methoden werden im Allow Header zurückgeliefert.
OPTIONS / HTTP/1.1
Host: www.w3.org
CONNECT
Die CONNECT-Methode kann verwendet werden um einem Proxy-Server mitzuteilen, sich direkt mit einem angefragten Zielsystem zu verbinden. Diese Methode spielt bei SSL-Verbindungen über Proxy-Server eine Rolle.
Sichere Methoden und Idempotente Methoden
HTTP als Protokoll ist zustandslos. Dennoch können über die genannten Request-Methoden Zustandsänderungen auf einem Zielsystem ausgelöst werden. Damit dies sowohl für die Client- als auch die Serverseite transparent erfolgt, sieht die HTTP-Spezifikation sichere und idempotente Methoden vor.
Als sichere Methoden gelten hierbei GET und HEAD. Sie sollen unter keinen Umständen Veränderungen auf dem angefragten System auslösen und dienen lediglich dem Abruf von Ressourcen. Dadurch kann den Methoden POST, PUT und DELETE eine klar getrennte, zustandsverändernde Funktion eingeräumt werden.
Idempotente Methoden müssen bei mehrfacher gleicher Ausführung (N > 0) immer das selbe Ergebnis zurückliefern. Hierzu gehören die Methoden GET, HEAD, PUT, DELETE, OPTIONS und TRACE. Beispiele hierfür sind das nur einmalige Erstellen oder Löschen einer Ressource beim wiederholten Aufruf des gleichen URI (eine Ressource unter demselben URI kann nicht mehrfach gelöscht werden).
Responses
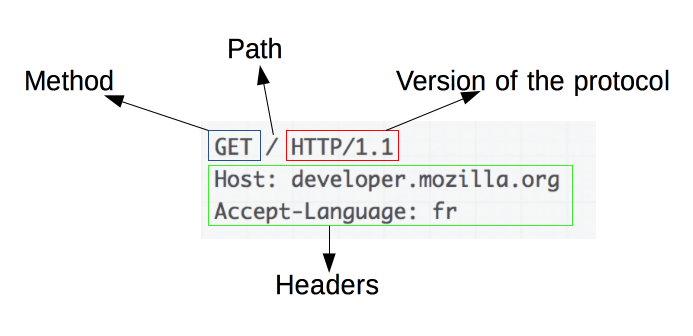
Eine HTTP-Response besteht aus folgenden verbindlichen Elementen: Der verwendeten Protokoll-Version, dem Status-Code, und einer Status-Message. Optional kann eine HTTP-Response zusätzliche Header sowie - je nach angefragter Methode - einen Body (Nachrichtenrumpf) enthalten.
Grafik: Bestandteile einer HTTP-Response
Quelle: MDN, https://developer.mozilla.org/en-US/docs/Web/HTTP/Overview/http_response.png
Header
Der angefragte Server schickt in seiner HTTP-Antwort ebenfalls spezifische Header an den Client. Nachfolgend eine kurze Übersicht über gängige Antwort-Header:
| Schlüsselwort | Werte (Beispiele) | Kurzbeschreibung |
|---|---|---|
Date |
Sun, 31 Dec 2017 12:20:58 GMT | Zeitpunkt des Absendens |
Connection |
Close/Keep-Alive | Status der HTTP-Verbindung |
Content-Encoding |
gzip | Ressourcen können vor dem Absenden vom Server aus Effizienzgründen komprimiert werden. Dieser Header gibt die Art der Komprimierung an, nicht den Zeichensatz, in dem der Inhalt kodiert ist |
Content-Length |
3495 | Länge des Nachrichtenrumpfes in Bytes |
Content-Type |
text/html; charset=utf-8 | MIME-Type des Nachrichteninhaltes mit Zeichensatz |
Location |
some/other/page.html | Im Falle von Weiterleitungen Ort der Ressource, auf die weitergeleitet wird |
Server |
Apache | Serverkennung |
Weitere Informationen
Statuscodes
Die HTTP-Spezifikation sieht vor, dass ein Server bei jeder HTTP-Antwort auch einen Statuscode mitliefert. Der Statuscode gibt Aufschluss darüber, ob eine Anfrage erfolgreich war, ob bestimmte Fehler aufgetreten sind (bspw. eine ungültige Anfrage des Client oder ein Softwareproblem auf dem Server) oder (im Falle von Umleitungen) wo bestimmte Ressourcen zu finden sind oder ob eine Authentifizierung für den Abruf bestimmter Ressourcen notwendig ist. Eine gute Kenntnis möglicher HTTP-Statuscodes ist insbesondere bei der webbasierten API-Programmierung wichtig:
HTTP-Statuscodes werden in fünf Bereiche eingeteilt.
1xx - Die Bearbeitung der Anfrage dauert noch an.
HTTP-Statuscodes in dieser Range werden verwendet, um dem Client eine noch nicht abgeschlossen Bearbeitung zu signalisieren und somit einen Timeout zu verhindern.
2xx - Die Anfrage war erfolgreich
In dieser Range finden sich Statuscodes, die eine erfolgreiche Anfrage signalisieren (insbesondere 200 - Ok und 201 - Created).
3xx - Weitere Schritte seitens des Clients sind erforderlich
Statuscodes aus dieser Range werden häufig bei Umstrukturierungen oder Umleitungen von Webseiten oder Web-APIs gesendet. Häufig anzutreffen sind die Codes 301 - Moved Permanently, 302 - Found (Moved Temporarily) und 303 - See Other. Der Location-Header in der HTTP-Antwort zeigt dem Client an, unter welcher URI die angefragte Ressource nun zu finden ist.
4xx - Ein Fehler ist aufgetreten. Die Ursache liegt (eher) im Verantwortungsbereich des Clients
HTTP-Statuscodes in dieser Range weisen Fehler aus, die häufig in Verbindung mit der Anfrage des Clients stehen. Besonders häufig ist der Statuscode 404 - Not Found, der verwendet wird, wenn eine angefragte Ressource nicht unter der entsprechenden URI gefunden werden konnte. Weitere häufig anzutreffende Statuscodes in dieser Range sind 403 - Forbidden (Zugriff für den Client verweigert) und 401 - Unauthorized (fehlende Authentifizierung für den Zugriff) und 400 - Bad Request (ungültige Anfrage).
5xx - Ein Fehler ist aufgetreten. Die Ursache liegt (eher) im Verantwortungsbereich des Servers
Die in dieser Range befindlichen HTTP-Statuscodes weisen Fehler aus, die (wahrscheinlich) auf dem Server bei der Verarbeitung der Anfrage geschehen sind. Gibt es beispielsweise auf dem Webserver, der die Anfrage verarbeitet, einen Fehler der dazu führt, dass die Anfrage nicht verarbeitet werden kann, wird der Fehlercode 500 - Internal Server Error zurückgegeben. Im Bereich von Webanwendungen kann dies häufig auch der Fall sein, wenn die Ausführung der jeweiligen Webanwendung, die für die Erzeugung des Inhalts der HTTP-Antwort verantwortlich ist, durch einen Programmfehler beendet wird. Bei hoher Auslastung eines angefragten Servers oder einer Fehlkonfiguration wird meistens der Statuscode 503 - Service Unavailable zurückgegeben.
Info
Ein einfacher Webservice zum Testen von HTTP-Requests ist https://httpbin.org.
Content Negotiation
Content Negotiation (etwa: “Inhaltsvereinbarung”) gehört zu den wichtigsten Konzepten in HTTP und beschreibt eine “Absprachemöglichkeit” zwischen Client und Server zur gezielten Auslieferung bestimmter Repräsentationsformen einer angefragten Ressource. Eine über eine URI adressierte Ressource verfügt als abstrakte Entität über keine eigene “Dinglichkeit”. Hinter einer URI können aber eine oder mehrere Repräsentationen für die Ressource stehen (bspw. in Form einer HTML-, XML- oder PDF-Datei).
In HTTP/1.1 kommt am häufigsten die serverseitige Content Negotiation zum Einsatz. Sie basiert auf den folgenden vier Request-Headern: Accept, Accept-Charset, Accept-Encoding und Accept-Language.

Grafik: Serverseitige Content Negotiation
Quelle: MDN, https://developer.mozilla.org/en-US/docs/Web/HTTP/Content_negotiation/httpnegoserver.png
Der Server antwortet auf diese vier Request-Header mit den drei Response-Headern Content-Type (enthält MIME-Type und Zeichensatz der Ressource), Content-Encoding (enthält Komprimierungsform) und Content-Language (enthält Sprachinformation). Sofern die ausgelieferte Repräsentation einer Ressource eine andere URL besitzt, kann der Server diese zudem über den Content-Location Header mitteilen.
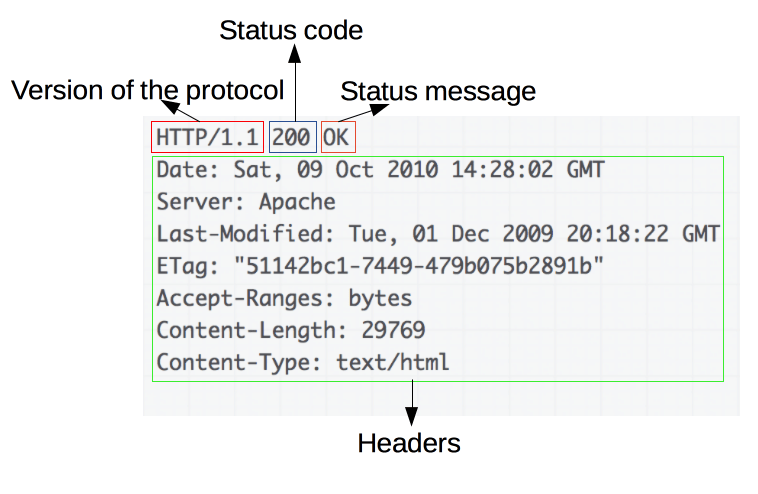
Anwendungsfälle für Content Negotiation bestehen beispielsweise in der Auslieferung sprachspezifischer Inhalte (Auslieferung einer Website in Französisch, wenn der Client den Accept-Language Header mit dem Wert “fr-FR” sendet) oder geeigneter Bildformate. Content Negotiation spielt auch im Semantic Web bei der Bereitstellung von RDF-Vokabularien und Ontologien sowie bei der Dereferenzierung von URIs eine wichtige Rolle.
Grafik: Dereferenzierung einer URI mittels Content Negotiation
Quelle: W3C, https://www.w3.org/TR/cooluris/img20081203/hash_conneg.png
Weitere Informationen
Authentfizierung
Sollen bestimmte Webinhalte nur für einen eingeschränkten Nutzer_innenkreis zugänglich sein, sind Authentifizierungsmechanismen notwendig. HTTP sieht hierfür mehrere Möglichkeiten vor. Generell erfolgt der HTTP-Authentifizierungsmechanismus gemäß RFC 7235 folgendermaßen:
- Ein Client fragt einen Server nach einer Ressource an
- Der Server antwortet mit Statuscode 401 - Unauthorized und sendet einen WWW-Authenticate Header
- Der Client antwortet mit einer erneuten Anfrage und einem Authorization Header, der die Zugangsdaten enthält
- Der Server prüft die Zugangsdaten und Antwortet entweder mit Statuscode 200 - Ok oder 403 - Forbidden
Innerhalb des WWW-Authenticate Headers legt der Server fest, welche Authentifizierungsmethode verwendet wird. Die grundsätzlichste Methode ist hierbei die HTTP Basic Authentication. Bei dieser Methode werden Benutzeridentifikation und Passwort in base64 Kodierung im Reintext übertragen. Daher sollte diese Authentifizierungsmethode ausschließlich in Verbindung mit verschlüsselten HTTPS-Verbindungen verwendet werden.
HTTP Authentifizierung findet direkt zwischen Client und Server statt und ist nicht zu verwechseln mit (weiteren) Authentifizierungsmechanismen, die auf der Ebene von Webanwendungen (bspw. ein datenbankgestütztes Login) stattfinden.
Weitere Informationen
Session Management
Da es sich bei HTTP um ein zustandsloses Protokoll handelt, bleiben Sitzungsinformationen zwischen ein und demselben Client und Server nicht über einen Request-Response-Zyklus hinaus erhalten. Funktionalitäten, die eine andauernde Sitzung benötigen (bspw. eine Login-Funktion, eine Warenkorb-Funktion etc.) müssen daher anwendungsseitig implementiert werden.
Protokolltechnisch geschieht dies durch die Generierung und das kontinuierliche Mitführen einer Session-ID. Hierbei muss die Anwendung einen eindeutigen Identifikator generieren, der vom Server an den Client übertragen wird und den dieser dann in allen folgenden Anfragen an den Server sendet. Dadurch kann der Server bzw. eine auf dem Server laufende Webanwendung den zugreifenden Client eindeutig identifizieren.
Das Management von Session-IDs kann in unterschiedlicher Weise erfolgen. Die einfachste Möglichkeit besteht im kontinuierlichen Mitführen der ID innerhalb von GET oder POST Requests. Bei GET-Requests erfolgt dies innerhalb einer Parameter:Wert Zuweisung im Query-Teil eines URI, bei POST-Anfragen beispielsweise in einem entsprechenden HTTP-Header. Beide Möglichkeiten bergen die Gefahr des Session Hijacking, also der unbefugten Übernahme einer Sitzung durch eine dritte Partei die in den Besitz einer gültigen Session-ID gelangt ist (zum Beispiel durch das Mitlesen der Informationen auf einem dritten System zwischen Client und Server, über das die jeweilige HTTP-Kommunikation läuft).
Die am häufigsten verwendete Methode zur Speicherung von Sitzungsdaten ist daher das HTTP-Cookie. Bei einem HTTP-Cookie handelt es sich um eine kleine Textdatei (maximale Größe 4KB), die vom Server mittels des Set-Cookie Headers an den Client versendet und dort (in Reintext) gespeichert wird. Ein Cookie kann neben der Session-ID auch noch weitere Sitzungsdaten enthalten, ist durch seine geringe Größe jedoch relativ eingeschränkt. Ein Server kann einem Client mehr als ein Cookie senden. Die Anzahl der Cookies pro Server ist jedoch auf 20 limitiert, insgesamt kann ein Client nicht mehr als 300 Cookies verwalten.
Praxis mit fortgeschrittenen HTTP-Konzepten
Die fortgeschrittenen Konzepte können gut mit Wikidata und unserem GitLab RLP trainiert werden.
1) Content Negotiation mit Wikidata
Nach dem Lesen der Beschreibung zum Datenzugriff in Wikidata kann mit beliebigen Entity-URIs Content Negotiation erprobt werden. Hierzu wird in RESTED die jeweilige Entity-URI (bspw. http://www.wikidata.org/entity/Q42) angegeben und entsprechende Accept Header (bspw. application/rdf+xml, application/ld+json etc.) gesendet.
2) Authentifizierung über die GitLab API
GitLab bietet eine ausgefeilte API für den Datenzugriff, welche sich sehr gut eignet, um HTTP Authentifizierungskonzepte zu erproben (z.B. für den Zugriff auf nicht-öffentliche Repositorien). Zunächst kann der Zugriff auf die GitLab REST API mit dem öffentlichen Repositorium der Slides von Modul Seven (Projekt ID 16368) erprobt werden (z.B. um sich mittels RESTED alle Mitglieder des Repositoriums anzeigen zu lassen). Der API-Einstiegspunkt für das GitLab RLP lautet https://gitlab.rlp.net/api/v4/. Als Nächstes soll das Team auf das eigene, nicht öffentliche Team-Repositorium in GitLab zugreifen. Dazu muss in den Einstellungen des Repos zunächst die Repositoriums-ID herausgefunden werden. Ohne Access Token wird beim Aufruf der URL zunächst nur ein Status 404 zurückgegeben – wir sind nicht authentifiziert für den Zugriff. Nun legen sich alle Teammitglieder in ihren Accounteinstellungen ein Personal Access Token an und senden dieses als Parameter mit – jetzt gelingt der Zugriff.
3) Inspektion von Cookies und Session für das GitLab
Der Storage Inspector von Firefox bietet einen strukturierten Überblick über die Cookies und die Sessions der aufgerufenen Websites. Alle Teammitglieder inspizieren mit dem Storage Inspector zunächst in eingeloggtem Zustand die Cookies und die dazugehörige Session für das GitLab RLP. Dann können bei geöffnetem Inspektor ein Logout und ein Login in das GitLab durchgeführt und die sich verändernden Cookie- und Session Daten beobachtet werden.
Weitere Informationen
APIs
HTTP wird nicht nur zur Übertragung von Webseiten verwendet. Es kann in Form sogenannter APIs auch direkt in Anwendungen zum Einsatz kommen. Hierbei werden HTTP-Anfragen nicht nur zum Abgruf von Daten in anderen Formaten als HTML benutzt, sondern auch, um in den Anwendungen bestimmte Aktionen (z.B. das Anlegen oder Löschen eines Datensatzes) auszulösen.
Das Akronym API steht für Application Programming Interface. Es bezeichnet eine Schnittstelle, über die Anwendungen miteinander kommunizieren können. Eine API kann dabei auf unterschiedlichen Ebenen angesiedelt sein. Sie kann bspw. auf der Betriebssystemebene (bspw. die Windows API), auf der Ebene von Programmiersprachen (bspw. die PHP API) oder auf der Ebene von Webanwendungen (bspw. bei Google Geocoding API) angesiedelt sein. In diesem Abschnitt geht es um die Verwendung von APIs zur Kommunikation zwischen Webanwendungen.
Info
Die Online-Version der Sturm-Edition verfügt über eine API, die Editions-Ressourcen wahlweise als HTML, JSON oder XML ausliefert:
Die im Modul 7 verwendete Sturm-App bezieht ihre Daten von dieser API.
RESTful APIs
Eine RESTful API im eigentlich Sinn ist eine API, welche die Prinzipien des Representational State Transfer (REST) einhält. REST ist ein Architekturstil für die Kommunikation zwischen Systemen des World Wide Web, der von Roy Fielding im Jahr 2000 in seiner Dissertation Architectural Styles and the Design of Network-based Software Architectures ausgearbeitet wurde. Beispiele für RESTful APIs sind die GitHub API und die GitLab API.
In der Praxis folgen viele sogenannte RESTful APIs nicht strikt den Prinzipien von REST; der Begriff bezeichnet stattdessen in einem weiteren Sinn APIs, bei denen HTTP zum Einsatz kommt.
RESTful API sind häufig (aber nicht immer) sogenannte CRUD APIs, welche die vier Grundoperationen Create, Read, Update und Delete auf Datenobjekte (sogenannte Ressourcen) bereitstellen. Die Operationen werden dabei über die HTTP-Methoden POST, GET, PUT und DELETE realisiert.
| Operation | HTTP-Methode |
|---|---|
| Create | POST, PUT* |
| Read | GET |
| Update | PUT, PATCH** |
| Delete | DELETE |
*) Die Spezifikation von PUT geht von Idempotenz aus, d.h. im Gegensatz zu POST sollte bei einer Create-Operation mit PUT das gleiche Datenobjekt bei mehrmaligem Request nicht mehrmals angelegt werden.
**) PUT wird häufig für vollständige Updates verwendet, PATCH für partielle Updates.
SOAP APIs
Eine weitere Möglichkeit, um APIs zu implementieren, ist die Verwendung von SOAP, dem Simple Object Access Protocol. Es basiert auf XML und ist ein Industriestandard, der von der W3C spezifiziert wurde. Moderne SOAP-Anwendungen verwenden i.d.R. HTTP, der Response-Body wird jedoch immer im XML-Format zurückgeliefert. Damit ist das Format von Inhalt und Metadaten vom eigentlichen Übertragungsprotokoll entkoppelt und die Maschinenlesbarkeit der Daten über unterschiedliche Übertragungssysteme hinweg gesichert.
Dabei zu beachten ist, dass die XML-Datenrepräsentation im Response-Body wiederum einen Header und einen Body hat. Diese sind nicht deckungsgleich mit Header und Body der Response-Nachricht, die HTTP verwendet. Der SOAP-Header enthält Metadaten, die der Kommunikation zwischen Client und Server dienen. Der SOAP-Body enthält die eigentlichen Daten, die zwischen Client und Server ausgetauscht werden.
HTTP/1.1 200 OK
Content-Type: text/xml; charset=utf-8
Content-Length: 696
<?xml version="1.0"?>
<soap:Envelope xmlns:soap="http://schemas.xmlsoap.org/soap/envelope/">
<soap:Header>
</soap:Header>
<soap:Body>
<GetCATPODInfoResponse xmlns="https://github.com/fpodschwadek/catpod">
<CATPODInformation>
<Name>CATPOD</Name>
<Author>Frodo Podschwadek</Author>
<GitHubURL>https://github.com/fpodschwadek/catpod</GitHubURL>
<Description>CATPOD is a tool designed for...</Description>
<License>EUPL-1.2</License>
<LatestVersion>1.2.2</LatestVersion>
</CATPODInformation>
</GetCATPODInfoResponse>
</soap:Body>
</soap:Envelope>
Datenformate
Wie an dieser Stelle bereits mehrfach angemerkt, spielen neben text/html als grundlegendem Inhaltsformat des Internet spielen weitere Datenformate vor allem bei der Kommunikation mit APIs eine wichtige Rolle: JSON und XML.
JSON
JSON steht für JavaScript Object Notation. Es handelt sich um ein textbasiertes Datenformat, das für den Datenaustausch zwischen Anwendungen verwendet wird. JSON ist ein Teilmenge von JavaScript und kann daher direkt in JavaScript-Code eingebettet werden. Es ist jedoch unabhängig von JavaScript und kann in vielen anderen Programmiersprachen für die Repräsentation von Ressourcen verwendet werden. Der mit JSON assoziierte Medientyp ist application/json.
{
"slideshow": {
"author": "Yours Truly",
"date": "date of publication",
"slides": [
{
"title": "Wake up to WonderWidgets!",
"type": "all"
},
{
"items": [
"Why <em>WonderWidgets</em> are great",
"Who <em>buys</em> WonderWidgets"
],
"title": "Overview",
"type": "all"
}
],
"title": "Sample Slide Show"
}
}
XML
XML steht für Extensible Markup Language. Es handelt sich um ein textbasiertes Datenformat, das für den Datenaustausch zwischen Anwendungen verwendet wird. XML ist eine Auszeichnungssprache und kann daher nicht nur zur Repräsentation von Daten, sondern auch zur Repräsentation von Dokumenten verwendet werden. Der mit XML assoziierte Medientyp ist application/xml oder text/xml (letzteres ist lediglich ein Alias des ersteren).
<?xml version='1.0' encoding='us-ascii'?>
<!-- A SAMPLE set of slides -->
<slideshow
title="Sample Slide Show"
date="Date of publication"
author="Yours Truly"
>
<!-- TITLE SLIDE -->
<slide type="all">
<title>Wake up to WonderWidgets!</title>
</slide>
<!-- OVERVIEW -->
<slide type="all">
<title>Overview</title>
<item>Why
<em>WonderWidgets</em> are great
</item>
<item/>
<item>Who
<em>buys</em> WonderWidgets
</item>
</slide>
</slideshow>
Praxis: HTTPocalypse Now
Mit Ihren bisher erworbenen Kenntnissen zu Docker, Infrastrukturen, PHP und Schnittstellen (und ein paar zusätzlichen Informationen) sind Sie nun in der Lage, sich lokal eine Testanwendung zu erstellen, die aus zwei Containern mit den Namen http-client und http-server besteht.
Verzeichnisse
Legen Sie sich zunächst ein neues Verzeichnis an (z.B. httpocalypse). Navigieren Sie in dieses Verzeichnis und erstellen Sie die beiden Unterverzeichnisse client und server.
HTTP-Server
Wechseln Sie in das Unterverzeichnis server.
Hier erstellen Sie eine neue Datei namens HttpController.php. Dies wird der Controller für die Webanwendung, die im HTTP-Server-Container laufen wird. Kopieren Sie folgenden Inhalt in die Datei und speichern Sie die Datei danach.
<?php
namespace App;
use Psr\Http\Message\{
ResponseInterface,
ServerRequestInterface
};
class HttpController {
public function __invoke(
ServerRequestInterface $request,
ResponseInterface $response,
array $args
) {
$response->getBody()->write('Hello World');
return $response;
}
}
Führen Sie nun (immer noch im server-Verzeichnis) einen Docker-Container mit folgenden Befehl von der Kommandozeile aus:
docker run -d -p 1010:1010 -v ./:/var/www/html/http-server/app --name http-server --rm registry.gitlab.rlp.net/studiengang-digitale-methodik/modul-7/php-http-server-base
Ob der Container erfolgreich gestartet ist, können Sie z.B. in der Container-Ansicht in Docker Desktop prüfen: Hier sollte nun ein Container namens http-server mit dem Status Running erscheinen. Auf der Kommandozeile können Sie dies mit docker ps --filter "name=http-*" prüfen.
Während der Container läuft, sollten sie auch die Nachricht “Hello World” sehen, wenn sie die URL http://localhost:1010 im Browser öffnen.
Wechseln Sie nun in das Unterverzeichnis client.
Hier erstellen Sie eine neue Datei namens test.php. Dies wird ein einfaches PHP-Script, mit dem Sie Requests verschicken und die Response-Daten auswerten können. Kopieren Sie folgenden Inhalt in die Datei und speichern Sie die Datei danach.
<?php
require __DIR__ . '/../vendor/autoload.php';
$client = new \GuzzleHttp\Client();
$response = $client->request(
'GET',
'host.docker.internal:1010',
[
'headers' => [
'User-Agent' => 'HTTP-Client-Container'
]
]
);
echo "Status Code: " . $response->getStatusCode() . "\n";
echo "Content-Type Header: " . $response->getHeaderLine('content-type') . "\n";
echo "Response Body: " . $response->getBody() . "\n";
Führen Sie nun (immer noch im client-Verzeichnis) einen weiteren Docker-Container mit folgenden Befehl von der Kommandozeile aus:
docker run -dit -v ./:/opt/app -w /opt/app --add-host host.docker.internal:host-gateway --name http-client --rm registry.gitlab.rlp.net/studiengang-digitale-methodik/modul-7/php-http-client-base
Ob dieser Container erfolgreich gestartet ist, können Sie auch wieder in der Container-Ansicht in Docker Desktop prüfen: Hier sollte nun ein Container namens http-client mit dem Status Running erscheinen. Auf der Kommandozeile können Sie dies ebenfalls mit docker ps --filter "name=http-*" prüfen, wo nun beide Container (Client und Server) ausgegeben werden sollten.
Sie können nun PHP-Skripts im client-Verzeichnis im Container http-client ausführen:
docker exec http-client php test.php
Das PHP-Skript aus der Datei test.php wird nun im Container http-client ausgeführt. Es verwendet einen HTTP-Client namens Guzzle, um einen GET-Request an den Server unsers http-server-Containers zu schicken. Die Response des Servers enthält die gleichen Daten, die Ihr Browser beim vorigen Aufruf erhalten hat. Diese werden vom PHP-Skript folgerndermassen ausgegeben:
Status Code: 200
Content-Type Header: text/html; charset=UTF-8
Response Body: Hello World
Dieses Setup gibt’s auch zum Anschauen als Video (ohne Ton):
Weitere Informationen
- In
http-serverläuft der PHP-eigene Entwicklungswebserver. Dieser leitet Anfragen an das PHP-Framework Slim weiter, welches Sie bereits aus der Sturm-App kennen. Für die untenstehenden Aufgaben benötigen Sie aus der Slim-Dokumentation Informationen aus dem Abschnitt zu Requests sowie zu dem Abschnitt zu Responses. Dabei geht es vor allem um die Methoden, die von den Request- und Response-Objekten zur Verfügung gestellt werden; ignorieren Sie gern alle Abschnitte zum Thema Middleware. - In
http-clientist der HTTP-Client Guzzle installiert, mit dem sich bequem HTTP-Requests aus einem PHP-Programm heraus verschicken lassen. Der Schnellstart und die Übersicht der Request-Optionen sind für die folgenden Aufgaben relevant. - In einem Docker-Container verweist
localhostauf die Umgebung innerhalb des gleichen Containers, darum kann Guzzle aushttp-clientheraus denhttp-servernicht über http://localhost:1010/ erreichen, wie Sie es im Browser können. Stattdessen kann in diesem Setup, wie intest.phpbereits zu sehen,host.docker.internalstattlocalhostverwendet werden.
Aufgaben
Sie können nun die PHP-Dateien für beide Container beliebig modifizieren, um das Verhalten des Request-Response-Zyklus zwischen beiden Containern zu beeinflussen.
-
Lassen Sie den Server wahlweise die Text-Nachricht “Hello World” oder den JSON-String
{"content": "Hello World"}zurückgeben. Letzteres soll ausgespielt werden, wenn der Client über einenAccept-Header JSON anfordert. (Werfen Sie hierfür gern einen Blick auf die PHP-Funktion zum Erstellen von JSON-Darstellungen) -
Verweigern Sie die Ausgabe, wenn der Client auf die gleiche Weise ein XML-Dokument anfordert. Schicken Sie mit der Response einen passenden Statuscode zurück.
-
Schicken Sie den Inhalt nur bei Requests zurück, die sich mit mit einem
Authorization: Basic-Header identifizieren (verwenden Sie als Usernamefoound als Passwortbar). Wenn kein passenderAuthorization-Header geschickt wird oder die Credentials nicht passsen, wird mit der Response kein Inhalt und ein passender Statuscode zurückgeschickt. Folgendes sollten Sie hierfür noch wissen:- Was ist Basic Authentication?
- Für den Client: die auth-Option für Guzzle
- Für den Server: die PHP-Funktionen zum dekodieren von base64-Strings und zum Teilen eines Strings anhand eines bestimmten Zeichens (in diesem Fall
:).
(Lösungen)